
Table of Contents
Understanding event-driven microservices architecture, its principles, and implementation for scalable systems.
Microservices architecture has emerged as a dominant approach for building scalable, modular, and resilient applications. Unlike monolithic applications, where all components are tightly coupled, microservices break down applications into smaller, independent services that communicate over well-defined APIs. This architectural shift enables organizations to build, deploy, and scale applications more efficiently, making it a preferred choice for enterprises transitioning from legacy systems to cloud-native solutions.
The importance of event-driven microservices is evident in industries that require real-time data processing and dynamic scalability. E-commerce platforms use EDA to handle inventory updates, payment processing, and personalized customer experiences. Internet of Things (IoT) applications leverage event-driven microservices for device telemetry and automation. Financial services rely on EDA for fraud detection, transaction processing, and risk assessment. Given these benefits, enterprises are rapidly embracing event-driven microservices. A 2023 Gartner report revealed that 74% of surveyed organizations have already implemented microservices, with another 23% planning adoption soon. Analysts further project that the microservices market will reach $10.86 billion by 2027.
In this article, we will explore the fundamentals of event-driven microservices, how they differ from traditional architectures, and their benefits, use cases, and challenges. By the end, you'll be equipped to evaluate whether an event-driven microservices architecture (EDMA) is the right fit for your applications.
What Are Event-Driven Microservices?
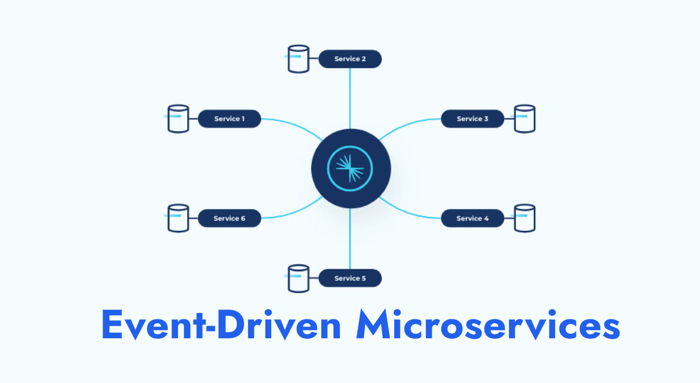
Event-driven microservices combine the principles of microservices architecture with event-driven architecture (EDA) to create systems that communicate through asynchronous events rather than direct service-to-service calls. In this approach, microservices produce and consume events, allowing for better decoupling, scalability, and resilience.

An event represents a change in state, such as a user placing an order on an e-commerce platform or a sensor detecting a temperature change in an IoT system. These events act as signals that trigger responses from other microservices without requiring direct communication. Events can either carry state information (such as order details) or serve as simple notifications (like a shipping status update).
Key Components of Event-Driven Microservices
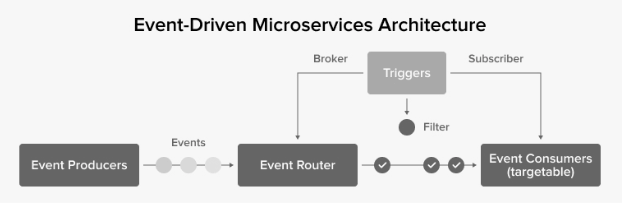
Producers: Producers are microservices that generate events when specific state changes occur. For example, an e-commerce service may emit an event when a customer adds an item to their cart. Producers do not need to know how events will be processed, allowing them to remain loosely coupled from other microservices.
Consumers: Consumers are microservices that listen for and react to events. They execute actions based on the event data they receive. For instance, when an “Order Placed” event is published, an inventory service might reduce stock levels, while a notification service sends an email confirmation to the customer.
Event Brokers (Routers): Event brokers act as intermediaries that manage the flow of events between producers and consumers. They enable reliable, scalable event distribution while ensuring services remain loosely coupled. Examples of popular event brokers include:
Apache Kafka – A distributed event-streaming platform widely used for real-time data processing.
RabbitMQ – A robust message broker designed for high-throughput messaging.
AWS EventBridge and Google Pub/Sub – Cloud-based event routing services for managing event-driven workflows.
Event-Driven vs. Traditional REST-Based Microservices
Traditional microservices architectures typically rely on synchronous RESTful APIs for inter-service communication, wherein a service issues a request to another and blocks until a response is received. This method is straightforward and effective for basic interactions but can lead to tight coupling between services, creating potential bottlenecks, particularly in scenarios where services experience latency or downtime.
In contrast, event-driven microservices adopt an asynchronous messaging paradigm, enabling services to operate independently by reacting to events as they occur rather than waiting for responses. This approach offers several advantages:
Improved scalability – Services can process events independently and scale dynamically.
Higher resilience – Failures in one service do not impact others as events can be queued and retried.
Greater flexibility – New services can be added without modifying existing services, as long as they subscribe to relevant events.
By adopting event-driven microservices, organizations can build systems that are more responsive, scalable, and adaptable to changing business needs.
Benefits of Event-Driven Architecture
Event-driven microservices architecture (EDMA) offers numerous advantages, primarily stemming from its asynchronous and decoupled nature. By enabling independent communication between microservices, EDMA enhances scalability, resilience, and agility while reducing costs and operational overhead.
Key Benefits
Improved Scalability: In an EDMA, microservices operate independently, allowing each service to scale up or down based on demand without affecting others. This ensures efficient resource utilization, reducing unnecessary infrastructure costs while maintaining high performance.
Easier Maintenance and Updates: Since microservices are loosely coupled, teams can update or replace individual components without disrupting the entire system. This modularity simplifies debugging, reduces the risk of cascading failures, and accelerates software maintenance cycles.
Faster Software Development Cycles: Developers can work on different microservices concurrently, reducing dependencies and conflicts. The ability to develop, test, and deploy services independently enables rapid iteration and quicker feature rollouts.
System Resilience: Failures in one service do not affect others, as services do not directly depend on each other for communication. An event broker (e.g., Kafka or RabbitMQ) acts as an intermediary, ensuring that events are processed even if certain services experience downtime.
Cost Reduction: Unlike synchronous architectures, EDMA does not require continuous polling for updates, reducing network and compute overhead. Dynamic scaling and optimized resource usage lower operational expenses.
Independent Scaling and Fault Isolation: Since services are not tightly integrated, they can fail or restart independently without causing system-wide outages. The event broker acts as a buffer, handling surges in workloads and ensuring reliable message delivery.
Agility and Flexibility: Developers no longer need to write complex polling logic or coordinate service-to-service calls. Event routers automatically filter and push events, enabling seamless integration of new microservices.
Enhanced Auditing and Security: The event broker provides a centralized point for auditing system activity and enforcing access policies. Security controls can be applied to restrict publishing and subscription permissions, ensuring secure event transmission.
When to and When Not to Use
Scenario | When to Use EDMA | When Not to Use EDMA |
Scalability Requirements | When microservices must scale independently based on demand. | When the system is small and does not require dynamic scaling. |
Parallel Processing Needs | When multiple services must process the same event concurrently (e.g., order fulfillment, notifications). | When event processing does not require parallel execution. |
System Resilience | When failure in one service should not impact others. | When a synchronous response is required for every request. |
Cross-Region or Multi-Account Synchronization | When data replication across regions or accounts is necessary (e.g., global applications). | When all services are tightly integrated and do not operate in multiple regions. |
Integration of Heterogeneous Systems | When services built on different technologies need to exchange information seamlessly. | When all services use a common stack and direct communication is feasible. |
Real-Time Monitoring and Alerting | When services need to react immediately to system events (e.g., fraud detection, IoT monitoring). | When event latency is unacceptable or immediate responses are mandatory. |
Strict Transactional Consistency | Not ideal for systems requiring strong consistency, as events are processed asynchronously. | When strong ACID compliance is needed (e.g., financial transactions). |
While event-driven architecture provides numerous benefits, it is not a one-size-fits-all solution. Its suitability depends on system complexity, scalability requirements, and the need for real-time event processing. Organizations should evaluate their use case carefully before adopting an EDMA-based approach.
Implementing Event-Driven Microservices
This section provides a hands-on guide to setting up an event-driven microservices architecture (EDMA) using Docker, Kafka, and Python (FastAPI + Kafka Python client). We'll build an order processing system where a producer emits order events, and a consumer processes them asynchronously.
Setting Up the Infrastructure
Step 1: Prepare the Environment
We use Docker and Docker Compose to set up Kafka and Zookeeper.
Install Docker & Docker Compose if not already installed.
Create a docker-compose.yml file for Kafka and Zookeeper:
version: '3.7'
services:
zookeeper:
image: confluentinc/cp-zookeeper:latest
environment:
ZOOKEEPER_CLIENT_PORT: 2181
kafka:
image: confluentinc/cp-kafka:latest
ports:
- "9092:9092"
environment:
KAFKA_ZOOKEEPER_CONNECT: "zookeeper:2181"
KAFKA_ADVERTISED_LISTENERS: "PLAINTEXT://kafka:9092"
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
depends_on:
- zookeeperRun Kafka and Zookeeper:
docker-compose up -dBuilding and Connecting Services
Step 1: Creating the Producer API (FastAPI)
We will create a FastAPI service to accept HTTP POST requests and publish order events to Kafka.
Producer Service (producer.py)
from fastapi import FastAPI
from kafka import KafkaProducer
import json
app = FastAPI()
producer = KafkaProducer(
bootstrap_servers="localhost:9092",
value_serializer=lambda v: json.dumps(v).encode("utf-8")
)
@app.post("/orders/")
async def create_order(order_id: int, product: str, quantity: int):
event = {"order_id": order_id, "product": product, "quantity": quantity}
producer.send("order_events", value=event)
return {"message": "Order created", "event": event}
# Run with: uvicorn producer:app --reloadNow, you can send order events via an API request:
curl -X POST "http://127.0.0.1:8000/orders/?order_id=1001&product=Laptop&quantity=2"Step 2: Creating the Event Consumer
The consumer listens for new order events and processes them.
Consumer Service (consumer.py)
from kafka import KafkaConsumer
import json
consumer = KafkaConsumer(
"order_events",
bootstrap_servers="localhost:9092",
auto_offset_reset="earliest",
value_deserializer=lambda m: json.loads(m.decode("utf-8"))
)
print("Consumer listening for order events...")
for message in consumer:
order = message.value
print(f"Processing Order: {order}")Step 3: Handling Event Schemas
To ensure consistency, use Apache Avro for event schemas.
Define an Avro Schema (order.avsc)
{
"type": "record",
"name": "Order",
"fields": [
{"name": "order_id", "type": "int"},
{"name": "product", "type": "string"},
{"name": "quantity", "type": "int"}
]
}Using Avro in Python
from fastavro import parse_schema, writer
schema = parse_schema(json.load(open("order.avsc")))
def serialize_order(order):
with open("order.avro", "wb") as out_file:
writer(out_file, schema, [order])We've successfully built a simple event-driven microservices system. This Kafka-based architecture ensures that order events are published by producers, consumed by services, and processed asynchronously, improving system scalability and resilience.
Challenges and Best Practices in Event-driven Microservices
While event-driven microservices offer scalability, resilience, and flexibility, they also introduce unique challenges. Unlike traditional request-response architectures, event-driven systems rely on asynchronous communication, making debugging, consistency, and observability more complex.
1. Ensuring Event Consistency and Idempotency
Problem: Events may be duplicated or processed out of order, leading to inconsistencies in system state.
Solution:
Use idempotent event handlers to ensure the same event does not cause unintended duplicate processing.
Implement event versioning (e.g., using an event schema registry like Apache Avro).
Store event logs in a database and track processed event IDs.
Example: Idempotent Processing with Redis
import redis
from kafka import KafkaConsumer
import json
redis_client = redis.Redis(host="localhost", port=6379, db=0)
consumer = KafkaConsumer("order_events", bootstrap_servers="localhost:9092", value_deserializer=lambda m: json.loads(m.decode("utf-8")))
for message in consumer:
order = message.value
event_id = order["order_id"]
if redis_client.exists(event_id):
print(f"Duplicate event {event_id} ignored.")
continue
redis_client.set(event_id, "processed")
print(f"Processing order: {order}") # Business logic hereThe consumer stores processed event IDs in Redis. If an event arrives again, it gets ignored.
2. Debugging and Monitoring in Asynchronous Workflows
Problem: Asynchronous systems are hard to debug because events flow between multiple services without direct tracing.
Solution:
Use distributed tracing tools like OpenTelemetry to track events across services.
Implement structured logging with correlation IDs for event tracking.
Use a message reprocessing strategy (e.g., retry mechanisms).
Example: Distributed Tracing with OpenTelemetry (FastAPI)
from fastapi import FastAPI
from opentelemetry.instrumentation.fastapi import FastAPIInstrumentor
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import ConsoleSpanExporter, SimpleSpanProcessor
app = FastAPI()
# Configure OpenTelemetry
trace_provider = TracerProvider()
trace_provider.add_span_processor(SimpleSpanProcessor(ConsoleSpanExporter()))
FastAPIInstrumentor.instrument_app(app, tracer_provider=trace_provider)
@app.get("/")
async def root():
return {"message": "Tracing Enabled"}OpenTelemetry collects traces and logs requests across services.
3. Managing Message Ordering and Delivery Guarantees
Problem: Some business processes require strict ordering of events (e.g., financial transactions).
Solution:
Use Kafka partitions with keys to ensure ordering per entity (e.g., per user ID).
Configure exactly-once semantics for event processing.
Example: Kafka Producer with Key-Based Ordering
producer.send("order_events", key=b"user123", value={"order_id": 101, "product": "Laptop"})Kafka ensures all messages with the same key (e.g., "user123") go to the same partition, preserving order.
Best Practices
To build reliable and scalable event-driven microservices, developers must follow best practices that ensure data integrity, fault tolerance, and observability. Since events are asynchronous and loosely coupled, failure handling and system monitoring require proactive strategies.
1. Use Dead-Letter Queues (DLQs) for Failed Events
When a consumer fails to process an event, move it to a DLQ instead of losing it.
Example: Kafka Dead-Letter Topic
kafka-topics.sh --create --topic order_events_dlq --bootstrap-server localhost:9092Consumers can retry processing events from this DLQ later.
2. Implement Observability with Distributed Tracing
Use tools like Jaeger, Zipkin, or OpenTelemetry for monitoring event flows.
Add trace IDs to logs for easy debugging.
Example: Log Correlation IDs
import logging
import uuid
logger = logging.getLogger(__name__)
def process_event(event):
trace_id = uuid.uuid4()
logger.info(f"Processing event {event['order_id']} | Trace ID: {trace_id}")By following these best practices, you can build a resilient event-driven microservices architecture!
Conclusion
Event-driven microservices have transformed contemporary software architecture, facilitating enhanced scalability, resilience, and real-time responsiveness. By decoupling services and employing asynchronous communication patterns, organizations can construct systems capable of processing high event throughput while maintaining fault tolerance and adaptability.
However, the transition to an event-driven architecture introduces several challenges, including ensuring event consistency, managing message orderings, and monitoring asynchronous workflows. The successful deployment of event-driven microservices hinges on meticulous system design, the selection of a suitable event broker, and the incorporation of comprehensive observability tools.
For developers aiming to adopt this paradigm, a prudent approach is to initiate a small-scale event-driven project. This allows for experimentation with event-handling strategies and facilitates iterative refinement. By progressively scaling their efforts, teams can effectively harness the full potential of event-driven microservices within their applications.
Akava would love to help your organization adapt, evolve and innovate your modernization initiatives. If you’re looking to discuss, strategize or implement any of these processes, reach out to bd@akava.io and reference this post.