

Table of Contents
A comprehensive guide to adopting self-healing infrastructure in DevOps(observability, automation, and cultural shifts).
In high-stakes development environments, the fragility of infrastructure isn't just a minor annoyance; it's a serious threat to survival. Traditional setups, where servers are treated like prized possessions that need constant hands-on care, simply can't keep up with the demands. These systems rely heavily on human oversight, and when something goes wrong, how quickly we can react often depends on whether a skilled engineer is available.
In industries where a single hour of downtime can cost anywhere from $301,000 to $400,000 (according to 2019 estimates), even a short outage can lead to massive financial losses. This isn't just about numbers; it means missed trading opportunities, delayed transactions, and a serious hit to client trust. It's clear that in this high-pressure landscape, letting infrastructure issues linger is simply not an option.
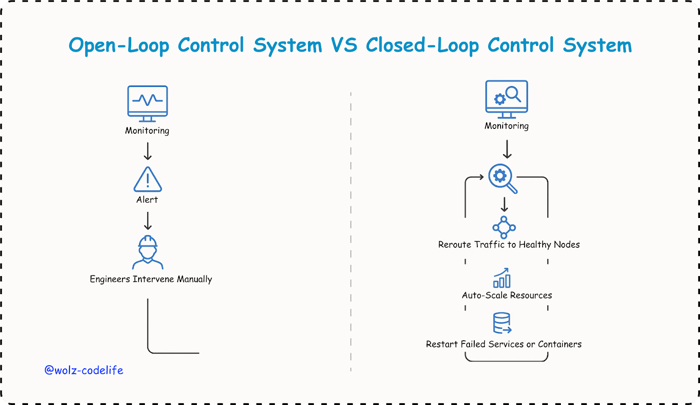
Much of today’s infrastructure still operates as an open-loop control system:
Monitoring detects anomalies.
Alerts are raised.
Engineers intervene manually.
This process, while familiar, is inherently reactive and vulnerable to delays especially during off-hours.
Self-healing infrastructure replaces this reactive model with a closed-loop control system. Here, detection, diagnosis, and remediation occur automatically. When a metric breaches a threshold, the system can:
Reroute traffic to healthy nodes.
Auto-scale compute resources.
Restart failed services or containers.
These actions take place automatically, eliminating the need for human approval and drastically reducing the time it takes to recover from issues, from hours down to just seconds.
Embracing self-healing technology isn’t just a step forward; it can give companies a real edge in a competitive landscape. In industries where every millisecond counts, being able to bounce back instantly is a game-changer. Transitioning from treating infrastructure like a cherished pet to adopting a more cloud-native, cattle-like approach has moved beyond being a mere innovation experiment; it’s now a necessity for effective operation.
What Is Self-Healing Infrastructure in DevOps?
Self-healing infrastructure is an exciting concept that draws inspiration from the Reactive Manifesto (2014). Imagine systems that can respond, bounce back, and stretch to meet challenges all on their own. This approach revolutionizes DevOps by enabling environments to detect, diagnose, and fix problems without needing a human to step in, allowing teams to shift from putting out fires to building resilience.
To illustrate this, think about how your heart naturally adjusts to the demands of exercise. When you push yourself, your heart rate increases, and as you rest, it slows down. This self-regulation helps keep you stable. In the same way, self-healing systems are designed to automatically regulate themselves and maintain their balance even when faced with stress. This kind of autonomic response is becoming essential for ensuring the reliability of our modern infrastructure.
Core Principles
At the core of self-healing infrastructure are some key principles that help systems run smoothly with little need for human oversight. These principles focus on early problem detection, quick resolution, and effective containment, all aimed at keeping services running without interruption. By using smart monitoring tools, automated recovery processes, and robust design approaches, self-healing systems shift from a reactive to a proactive way of operating. This transformation is crucial for high-pressure environments like the finance sector, where reliability is essential.
Self-healing infrastructure rests on the following principles:
Automatic Detection: Continuous, AI-augmented monitoring uncovers anomalies before they impact service quality.
Automated Diagnosis & Recovery: Predefined remediation workflows execute corrective actions (e.g., restarting services, reallocating workloads) without human input.
Built-in Resilience: Redundancy, fault tolerance, and graceful degradation prevent single points of failure and minimize disruption.
Distinguishing Self-Healing
While high availability (HA) and auto-scaling are important for keeping systems reliable, self-healing infrastructure takes a more comprehensive and proactive approach. HA is mainly about ensuring that things keep running smoothly by having backup systems in place; it reacts to failures when they happen, but doesn’t do much ahead of time. Auto-scaling focuses on adjusting the system’s resources to handle changes in demand, but it doesn’t fix underlying issues like software bugs or configuration mistakes. On the other hand, self-healing infrastructure works like a well-oiled machine. It constantly monitors the system, and when something goes wrong, it doesn’t just fix it after the fact; it identifies and addresses problems on its own, all without needing any human help.
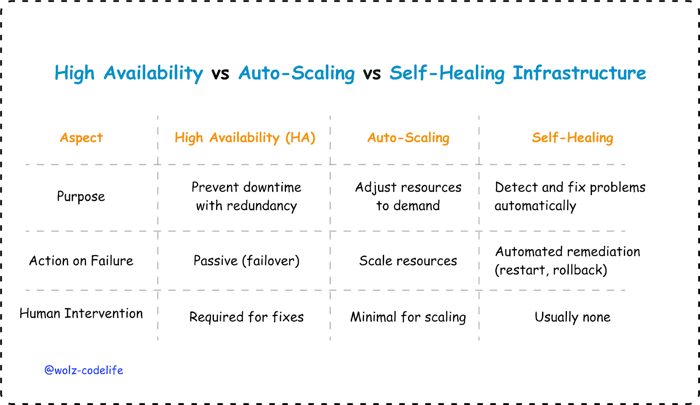
This integrated and automated response model allows for self-healing infrastructure, making it particularly well-suited for environments where both reliability and agility are crucial, like in financial services. In these settings, any downtime can lead to considerable operational and financial risks, so having a system that can automatically address issues is essential.
Observability Foundations for Self-Healing
At the heart of a successful self-healing system is observability, the ability to understand what’s happening in real-time. It’s essential to have accurate and timely insights; without them, automated fixes can end up going awry, leading to mistakes, false alarms, or even overlooking significant problems.
The Three Pillars

Self-healing systems ingest three fundamental telemetry types:
Logs: Detailed event records capturing system behaviors, errors, and state changes. Essential for diagnosing incidents and pattern detection.
Metrics: Quantitative indicators, CPU load, latency, and error rates that enable rapid anomaly detection against predefined thresholds.
Distributed Tracing: Maps transaction flows across microservices or components, crucial for pinpointing root causes in complex, distributed architectures.
Centralized Telemetry and Correlation IDs
Modern observability platforms like OpenTelemetry, Datadog, and Splunk help us make sense of complex data by bringing everything together into easy-to-read dashboards. They use unique correlation IDs that connect logs, metrics, and traces to specific transactions or sessions. This way, if something goes wrong, like a failed financial transaction, we can track the issue across different services. It even allows for automatic rollbacks or retries without needing any manual steps, making everything smoother and more efficient.
Meaningful Health Signals & SLOs
Critical to automation success is discerning which signals warrant action. Service Level Objectives (SLOs) translate business risk into measurable thresholds; only breaches that threaten agreed-upon uptime or latency trigger remediation. For instance:
A latency spike beyond 250ms on a trading API may invoke traffic rerouting.
Elevated CPU during batch processing might be ignored if within the expected variance.
Example: Automating Remediation with Runbook-as-Code
apiVersion: batch/v1
kind: Job
metadata:
name: restart-service
spec:
template:
spec:
containers:
- name: restart
image: bitnami/kubectl
command: ["kubectl", "rollout", "restart", "deployment/my-app"]
restartPolicy: OnFailureThis Kubernetes job is designed to automatically restart a deployment when it detects a health issue, like an error spike. This proactive approach helps reduce the Mean Time to Resolution (MTTR) and minimizes the impact of downtime.
For financial institutions, where even a short period of downtime can lead to significant losses, having robust observability is essential for managing risks. It acts like an "invisible engineer," constantly monitoring systems with the help of AI. This ensures that any issues are identified and resolved quickly, maintaining operational continuity and preserving client trust.
Automation & Remediation Patterns
Automation plays a vital role in creating self-healing infrastructure. In the financial sector, where downtime can cost over $300,000 per hour, having the ability for quick, automatic fixes can greatly reduce disruptions and protect essential operations. By establishing clear response patterns, automation not only reduces tedious manual work but also enhances the accuracy and reliability of systems.
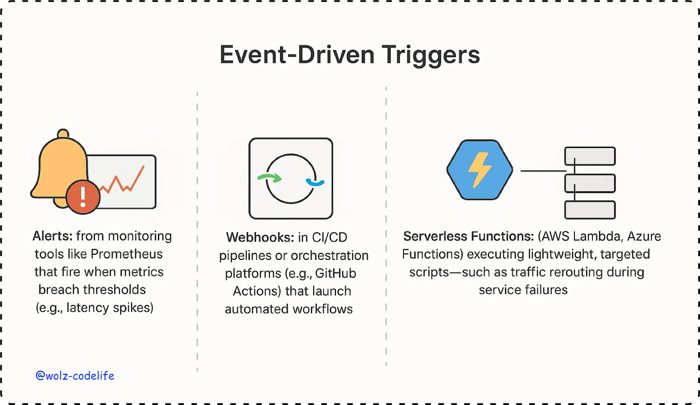
Event-Driven Triggers
Self-healing systems initiate remediation through event-driven triggers, including:
Runbook Automation vs. Policy-as-Code
Automation is typically implemented in two complementary ways:
Runbook Automation: Scripted operational procedures executed by platforms like Rundeck or Kubernetes Jobs. Example: Automatically restarting a failing service.
Policy-as-Code: Declarative governance embedded directly into infrastructure, enforced by tools like Open Policy Agent (OPA), which validate configurations and prevent deployment errors.
package kubernetes.admission
deny[msg] {
input.request.kind.kind == "Pod"
not input.request.object.spec.containers[_].resources.limits
msg := "All pods must have resource limits defined"
}Common Self-Healing Actions
Auto-Restart: Restart failed services or pods to restore availability.
Auto-Scale: Adjust resources dynamically in response to demand (e.g., Kubernetes Horizontal Pod Autoscaler).
Circuit Breakers: Temporarily block requests to malfunctioning components, preventing failure cascades.
Feature Toggles: Disable problematic features on the fly without redeploying, preserving user experience.
Safeguards to Mitigate Risk
Given the high stakes in finance, automation must include:
Blast Radius Controls: Restrict automated actions’ scope (e.g., restart only the affected node, not the entire cluster) to prevent widespread impact.
Rollback Strategies: Automated rollback mechanisms revert systems to known stable states if remediation fails or causes regressions.
When well-designed, automation transforms incident response from reactive firefighting into proactive risk mitigation. It complements engineers by handling repetitive recovery tasks, allowing them to focus on architectural improvements and strategic innovation. For financial institutions, this shift translates into reduced downtime risk, consistent service availability, and improved operational leverage, critical advantages in fast-moving markets where every second counts.
Embedding Self-Healing in DevOps Culture & CI/CD
Technology on its own can't fulfil the potential of self-healing infrastructure; it needs to be woven into the fabric of DevOps culture and the way we deliver our projects to truly achieve lasting resilience. Making this change requires a thoughtful approach to how teams create, test, and manage automated processes for fixing issues.
The following are practices for embedding self-healing in DevOps culture:
Shifting Left: It's important to validate self-healing systems early on, before they go live. By incorporating remediation tests into our CI/CD pipelines, we can mimic various fault conditions like service crashes, spikes in latency, or issues with dependencies. This way, we can ensure that our automated recovery methods, like auto-scaling and service restarts, actually work as they should. This proactive approach helps us avoid the risks that come with deploying untested automation, keeping our systems more reliable and robust.
name: Test Remediation
on: [push]
jobs:
test-remediation:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Simulate Failure and Test Auto-Scale
run: |
kubectl apply -f test/failure-simulation.yaml
kubectl wait --for=condition=ready pod -l app=test-appBlameless Postmortems and Continuous Feedback: After various incidents have occurred, it's important to conduct postmortems that focus on learning from the experience rather than placing blame. This means taking a close look at what caused the issues and how well our automated solutions worked in response. By using data collected from telemetry, we can create feedback loops that allow us to refine our healing rules. This involves fine-tuning the thresholds and adjusting how aggressively we respond to problems, all to improve the overall reliability of our systems.
Governance: In industries like banking and insurance, it's crucial that automated fixes meet strict regulations. To ensure this, governance frameworks are integrated into continuous integration and delivery (CI/CD) processes, which means that only approved automation can be used. Tools like Open Policy Agent help enforce compliance automatically, allowing organizations to stay nimble while effectively managing risks.
Training and Runbook Evolution: To foster sustainable self-healing within our teams, we must become fluent in automation tools, observability practices, and incident modeling. Rather than sticking to the old way of using traditional runbooks, we’re now reimagining them as executable code for our infrastructure. This means leveraging tools like Terraform and Kubernetes manifests to create clear and actionable workflows for addressing issues. The great thing about this approach? It helps us maintain our recovery procedures in a way that’s version-controlled, testable, and always evolving.
Integrating self-healing into the DevOps culture not only speeds up recovery times but also nurtures a proactive mindset around reliability. This is particularly important for financial institutions, where outages can incur costs of over $300,000 per hour. By embedding this culture, we can protect service continuity and enable teams to focus on meaningful innovation rather than constantly putting out fires.
Conclusion
Transitioning to self-healing infrastructure goes beyond just using the right tools; it’s all about creating a culture that prioritizes seamless integration of observability, disciplined automation, and continuous improvement. When organizations align clear health indicators with event-driven responses and strict governance, they can significantly shorten the time it takes to detect and recover from issues, turning downtime from a regular hassle into an uncommon occurrence.
The journey to success is best approached step by step. Start by automating low-risk fixes, validate them in CI/CD pipelines, and then gradually expand as confidence in the systems builds. Over time, these automated processes shift from being safety nets to becoming proactive systems that enhance resilience, allowing teams to focus on innovation while protecting crucial revenue and reputations.
At its core, self-healing infrastructure transforms DevOps practices within the financial sector by embedding observability, automation, and cultural shifts into daily operations. Key aspects to focus on include strong telemetry, event-driven triggers, and remediation methods like auto-scaling and circuit breakers. A culture that emphasizes learning from mistakes through blameless postmortems and governance is essential for ongoing improvement. By tracking metrics like Mean Time to Detect (MTTD) and Mean Time to Recovery (MTTR), organizations can ensure they meet stringent uptime requirements, considering the significant costs associated with outages. The way forward involves a careful and gradual implementation, paired with continuous adjustments to respond to changing business needs.
Akava would love to help your organization adapt, evolve and innovate your modernization initiatives. If you’re looking to discuss, strategize or implement any of these processes, reach out to bd@akava.io and reference this post.


