Learn how to leverage cloud-native infrastructure in machine learning
The integration of Artificial Intelligence (AI) and Machine Learning (ML) into modern applications is driving innovation across various industries. Cloud-native AI, which is a development approach that leverages cloud computing principles for AI workloads, has emerged as a powerful tool for building and deploying these intelligent systems. By harnessing the scalability and elasticity of cloud resources, cloud-native AI enables organizations to efficiently manage complex AI models and workflows.
At the core of cloud-native AI deployments lies Kubernetes, which is an open-source container orchestration platform. Kubernetes facilitates the management and automation of containerized applications, which is a key concept in cloud-native development. For AI and ML workloads, Kubernetes offers several advantages. It streamlines the deployment and scaling of AI models, ensures efficient resource utilization, and promotes a more agile and collaborative development process for data scientists and engineers. This introduction lays the groundwork for exploring how Kubernetes empowers cloud-native AI and revolutionizes the landscape of intelligent application development.
Understanding Kubernetes for AI/ML Workloads
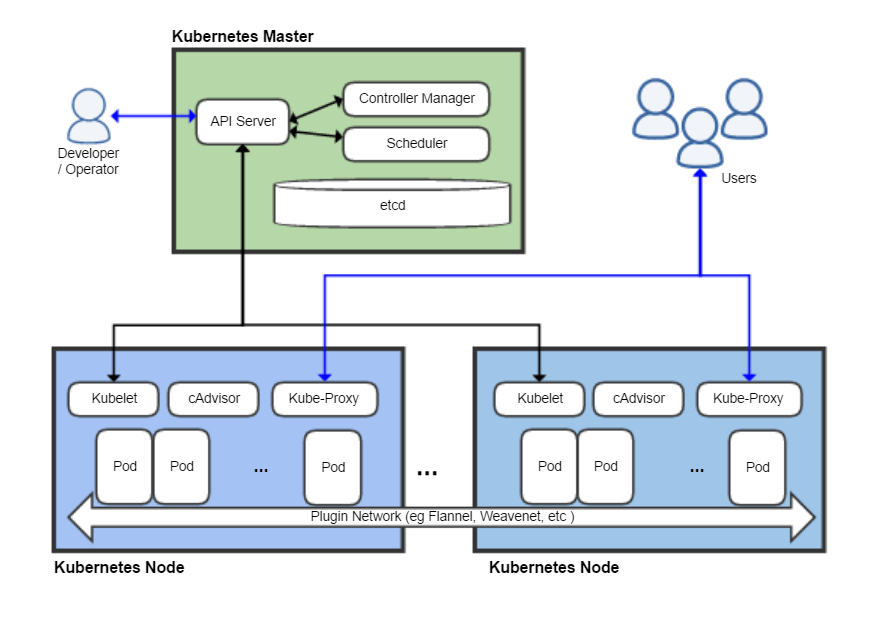
Kubernetes is an open-source platform designed to manage containerized workloads and services. Its modular architecture is highly effective for running AI and ML applications. At its core, Kubernetes operates on a cluster of nodes, where each node hosts pods, which are the smallest deployable units that can be created, scheduled, and managed. The cluster is managed by a master node, which handles scheduling, scaling, and deployment of workloads across worker nodes. The architecture is designed to optimize resource utilization, manage service discovery, and automate the scaling and healing of applications.
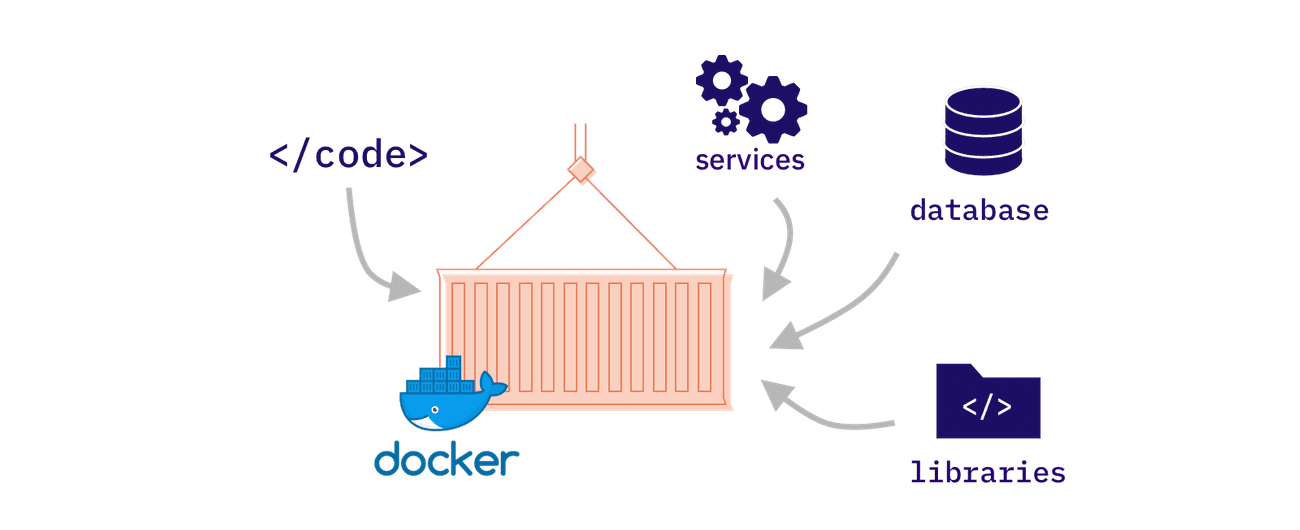
Docker is a software tool that facilitates the building and deployment of applications. It provides isolated environments to host multiple applications developed by different developers using different versions of Python. By using Docker, we can create three separate environments for each application and its dependencies. Docker containers are similar to shipping containers used in the transportation of goods, as they offer an isolated environment for the items being transported. A Docker image is a read-only file that contains the application and its dependencies, while a Docker container is a running instance of the image that can be used to run multiple containers with a single image.
Kubernetes has relevance to AI/ML workloads due to its capability to support complex computational tasks and data processing workflows that are commonly found in AI and ML projects. Kubernetes streamlines the deployment of these workloads by providing a consistent environment for development, testing, and production. It enables seamless scaling of AI/ML applications to handle large datasets and computational tasks efficiently, ensuring that resources are dynamically allocated based on demand.
Benefits of Using Kubernetes for AI/ML
- Scalability: Kubernetes excels in handling the dynamic nature of AI/ML workloads, which often require significant computational resources that can fluctuate over time. It allows for automatic scaling of applications and resources, enabling organizations to efficiently manage workloads of any size without compromising performance.
- Efficiency: By optimizing the utilization of underlying infrastructure, Kubernetes ensures that resources are not wasted. It intelligently schedules jobs and allocates resources, thereby reducing operational costs and improving the efficiency of AI/ML pipelines.
- Portability: Kubernetes provides a consistent environment across various infrastructures, whether on-premises, in the cloud, or in a hybrid setting. This portability ensures that AI/ML applications can be developed once and deployed anywhere, facilitating easy migration and deployment across different environments.
- Fault Tolerance: Kubernetes enhances the reliability of AI/ML applications by automatically managing service health, restarting failed containers, and replicating instances across the cluster. This ensures high availability and fault tolerance, minimizing downtime and disruption in AI/ML operations.
Kubernetes' architecture and capabilities make it an indispensable tool for managing AI/ML workloads. Its ability to provide scalability, efficiency, portability, and fault tolerance addresses the critical challenges faced in deploying and managing AI/ML applications, thereby enabling organizations to leverage the full potential of their AI and ML initiatives.
Deploying ML Models on Kubernetes
Deploying Machine Learning (ML) models on Kubernetes allows for scalable, efficient, and robust applications. Here's a step-by-step guide to deploying an ML model using Kubernetes, demonstrating the process with a Docker container and highlighting the role of Kubeflow in this ecosystem.
Prerequisites:
- Docker Desktop installed with Kubernetes enabled.
- Basic understanding of Docker commands.
Step 1: Set Up Your Environment
Before starting, ensure Docker Desktop is installed and Kubernetes is enabled in its settings. Verify Docker's installation by opening a terminal and running:
Step 2: Pull the Docker Image
Pull the Docker image that contains the ML model. In this example, we're using `user001/classification-app` from Docker Hub:
Step 3: Check the Image and Tag It
Verify the image is pulled successfully and tag it for deployment:
Step 4: Run the Docker Container
Start the Docker container to ensure the ML model is running correctly:
Step 5: Test the Model Locally
Create a `predict-test.py` script to send a sample payload to the model for prediction. The script looks like this:
Run the script:
Step 6: Deploying on Kubernetes with Minikube
Install Minikube and kubectl to work with Kubernetes locally. Start Minikube:
Check its status to ensure it's running correctly:
Step 7: Create Kubernetes Deployment and Service
Define your deployment and service in `.yaml` files. These files describe how your application should be deployed and how to expose it to the outside world. For this example, refer to the provided GitHub repository for `deployment.yaml` and `service.yaml` content.
Deploy your ML model on Kubernetes:
Verify the deployment and service are up and running:
Step 8: Access the ML Application
Find the URL to access your deployed application:
Update the `predict-test.py` script with the new URL and run it again to test the deployed model.
Step 9: Clean Up
After testing, remove the deployment and service:
Stop and delete Minikube to clean up local resources:
Jupyter Notebooks and Kubernetes
Integrating Jupyter Notebooks with Kubernetes facilitates managing ML workflows more effectively, allowing data scientists to work within a scalable and accessible environment. Kubernetes enhances the functionality of Jupyter Notebooks by providing:
- Scalability: Dynamically allocate resources based on the computational needs of different notebooks.
- Accessibility: Access Jupyter Notebooks from anywhere, leveraging Kubernetes' portability.
- Collaboration: Share work environments and experiments easily within teams.
This integration supports a more efficient development and deployment pipeline for ML models, enabling data scientists to focus on innovation rather than infrastructure management.
Scaling AI/ML Workloads on Kubernetes
Scaling AI/ML workloads efficiently is crucial for optimizing resource utilization and performance in response to varying demands. Kubernetes offers several mechanisms to scale workloads dynamically: Horizontal Pod Autoscaler (HPA), Vertical Pod Autoscaler (VPA), and Cluster Autoscaler. Each method serves distinct use cases and provides specific benefits for managing AI/ML workloads.
Horizontal Pod Autoscaler (HPA)
HPA automatically scales the number of pods in a deployment or replica set based on observed CPU utilization or other selected metrics. HPA adjusts the workload to match the demand by increasing or decreasing the number of pods.
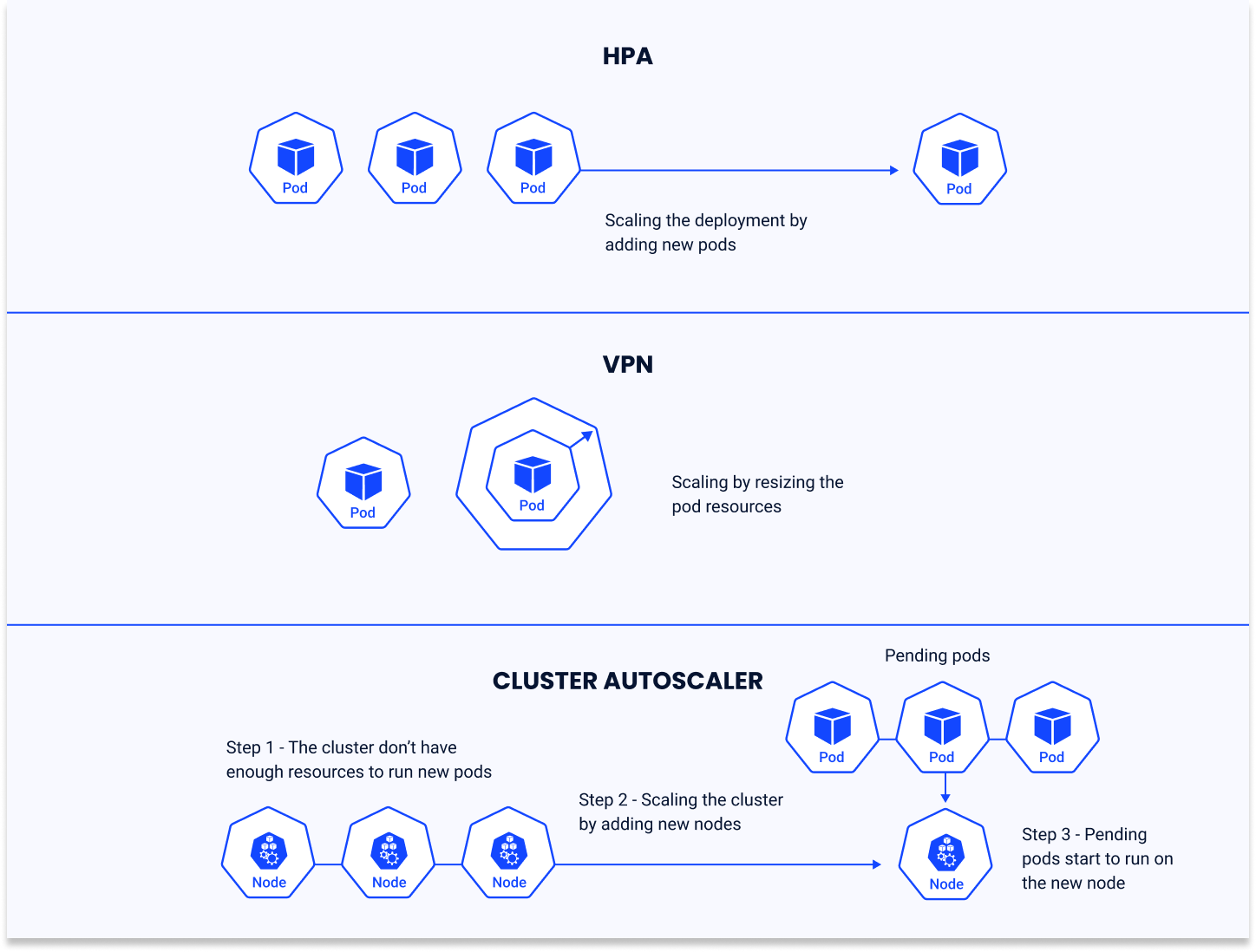
Use Cases
HPA is particularly useful for stateless applications where adding more instances of the application can handle increased load. This is common in ML inference services, where the load can vary significantly over time.
Benefits
The primary benefit of HPA is its ability to maintain performance under varying loads without over-provisioning resources, leading to cost savings. It ensures that the number of pods always matches the current demand as closely as possible.
Vertical Pod Autoscaler (VPA)
VPA adjusts the CPU and memory allocations for pods in a deployment, replica set, or stateful set, based on usage. Unlike HPA, which scales out horizontally, VPA scales the resources vertically by changing the resource limits of the pods.
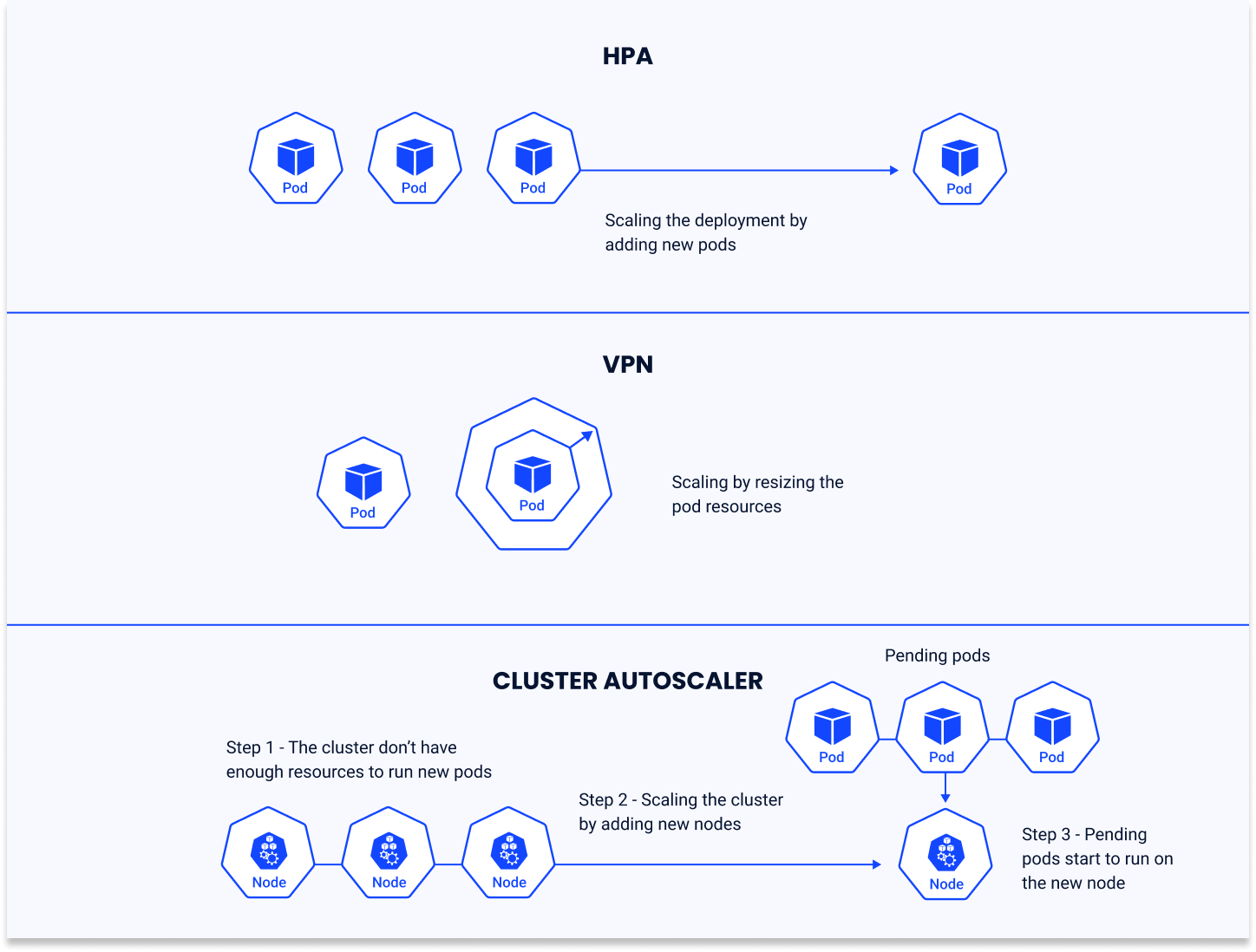
Use Cases
VPA is suitable for applications that are not easily scaled by increasing the number of pods. It is particularly beneficial for workloads that have variable resource requirements over time, such as batch processing jobs in ML and data analysis tasks.
Benefits
VPA optimizes the resource utilization of pods, ensuring they have enough resources to perform efficiently without wasting computational power. It automates resource allocation, simplifying the management of pods with fluctuating resource needs.
Cluster Autoscaler
The Cluster Autoscaler dynamically adjusts the size of the Kubernetes cluster by adding or removing nodes based on the demand. It ensures that all pods have a place to run and that there are no unneeded nodes consuming resources.
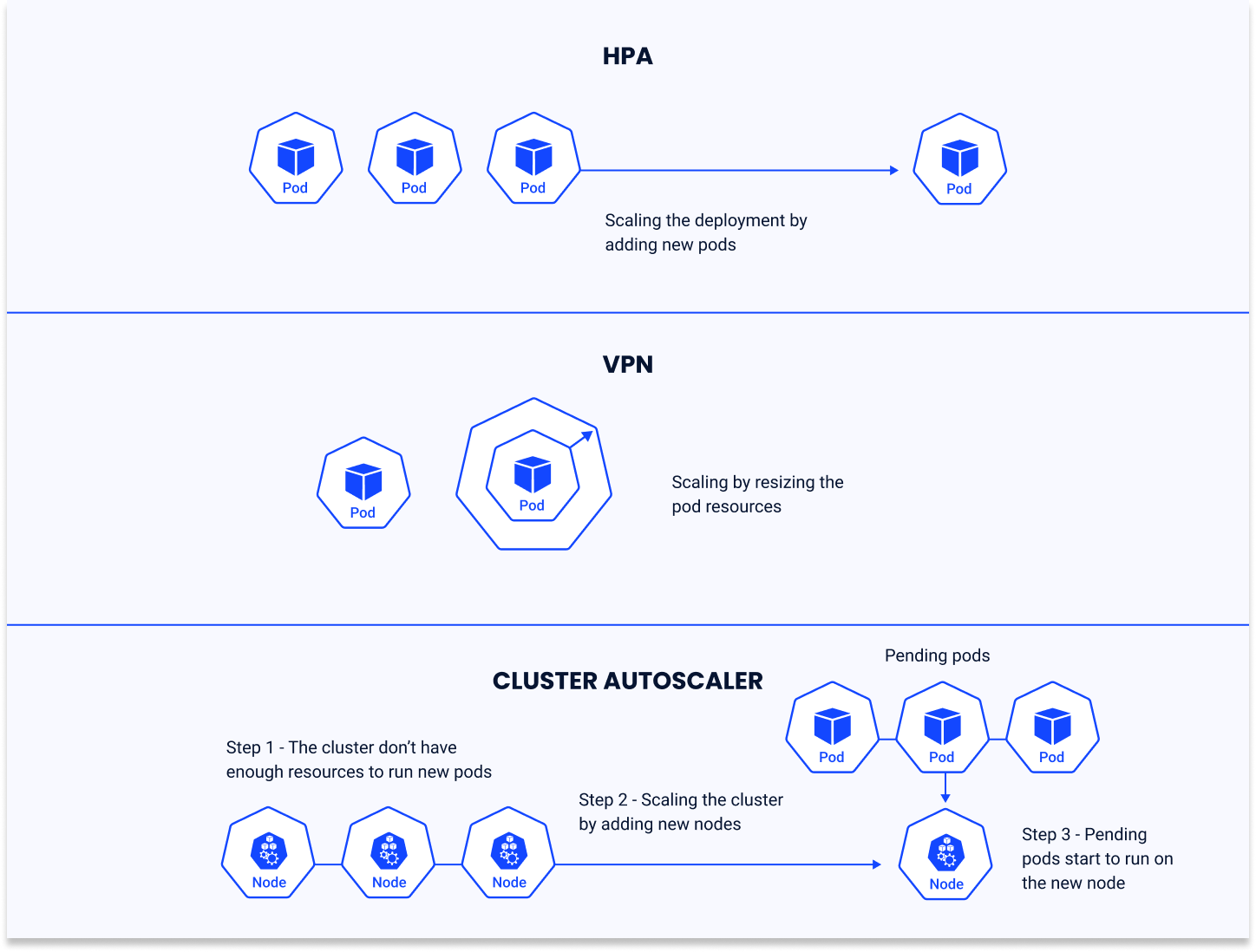
Use Cases
Cluster Autoscaler is essential when the workload exceeds the current capacity of the cluster, or when there's a need to scale down to reduce costs. It's crucial for large-scale AI/ML applications that might require rapid scaling up to handle intensive computational tasks.
Benefits
The main advantage of using Cluster Autoscaler is its ability to automatically manage the underlying infrastructure, ensuring that the cluster's size is always optimized for the current workload. This not only improves resource utilization but also reduces costs by eliminating idle resources.
Challenges and Solutions in AI/ML Deployment
Deploying AI/ML workloads on Kubernetes presents unique challenges, largely due to the complexity of ML workflows and the resource-intensive nature of these tasks. Understanding these challenges and the Kubernetes solutions can greatly enhance the efficiency and reliability of AI/ML deployments.
Common Challenges in AI/ML Deployment
- Complex Dependency Management: AI/ML applications often rely on a specific set of libraries and environments, making deployment complex and prone to errors.
- Resource Intensity: Training models are resource-intensive, requiring significant CPU, GPU, and memory resources, which can lead to resource contention and inefficiencies.
- Scalability Issues: AI/ML workloads can have variable computational needs, requiring scalable infrastructure to efficiently handle workload spikes.
- Pipeline Complexity: ML workflows encompass data preprocessing, training, evaluation, and inference, each with distinct resource and runtime requirements, complicating the deployment and management process.
- Development and Production Parity: Ensuring consistency between development environments and production deployments is challenging, which can lead to issues when models are moved into production.
Kubernetes Solutions to Deployment Challenges
- Reusable Deployment Resources: Kubernetes offers a templated approach to deployment through manifests and Helm charts, enabling the creation of reusable and consistent deployment patterns. This helps in managing complex dependencies by standardizing environments across development and production.
- Automated Scaling: Kubernetes provides automated scaling solutions like Horizontal Pod Autoscaler (HPA), Vertical Pod Autoscaler (VPA), and Cluster Autoscaler. These tools dynamically adjust resources and infrastructure to meet the demands of AI/ML workloads, ensuring efficient resource utilization without manual intervention.
- Efficient Resource Management: Kubernetes supports the efficient allocation of resources through namespaces, quotas, and limits, preventing resource contention and ensuring that critical workloads have the resources they need. Additionally, Kubernetes' support for GPU scheduling and allocation is crucial for ML workloads.
- Streamlined Workflow Orchestration: Kubernetes can orchestrate complex ML pipelines using tools like Kubeflow, which simplifies the management of end-to-end ML workflows on Kubernetes. Kubeflow provides components for each stage of the ML pipeline, from data preprocessing to model training and serving, ensuring seamless workflow management.
- Infrastructure Abstraction and Flexibility: Kubernetes abstracts the underlying infrastructure, providing a consistent environment for deploying AI/ML applications across different clouds or on-premises environments. This flexibility helps in maintaining development and production parity, simplifying deployments across varied environments.
- Continuous Integration and Continuous Deployment (CI/CD): Integrating Kubernetes with CI/CD pipelines automates the testing, building, and deployment of AI/ML applications, further reducing the gap between development and production environments. This ensures that models are quickly and reliably deployed, facilitating rapid iteration and innovation.
While deploying AI/ML workloads on Kubernetes comes with its set of challenges, Kubernetes offers a robust set of solutions to address these issues. By leveraging Kubernetes' capabilities, organizations can overcome the complexities of AI/ML deployment, ensuring that their applications are both efficient and resilient.
Conclusion
Organizations looking to future-proof their AI/ML deployments and maximize operational efficiency should consider adopting Kubernetes. The platform’s ability to abstract away the complexities of the underlying infrastructure, coupled with its comprehensive toolset for managing containers at scale, allows developers and data scientists to focus more on innovation and less on operational challenges. As we look to the future, the synergy between Kubernetes and cloud-native AI will undoubtedly continue to deepen, paving the way for more advanced, efficient, and scalable AI/ML solutions.
In conclusion, the evolution of Kubernetes and its growing role in supporting cloud-native AI and ML workloads is a testament to its foundational importance in the modern technology landscape. Organizations that embrace Kubernetes for their AI/ML projects will not only be better positioned to leverage the full potential of their data and computational resources but also stay ahead in the rapidly advancing field of artificial intelligence. The time to adopt Kubernetes and unlock the transformative power of cloud-native AI is now.
Akava would love to help your organization adapt, evolve and innovate your modernization initiatives. If you’re looking to discuss, strategize or implement any of these processes, reach out to bd@akava.io and reference this post.