Learn best practices when using DevOps for machine learning pipelines
DevOps emerges as a transformative methodology, emphasizing collaboration, automation, continuous integration, and continuous delivery. This approach aims to shorten the development lifecycle, enhance deployment frequency, and ensure a high release quality, facilitating a more agile and efficient production process. By fostering a culture of shared responsibility between development and operations teams, DevOps breaks down traditional silos, enabling faster feedback, and more rapid iteration.
As the focus shifts towards incorporating artificial intelligence and machine learning (ML) into software solutions, the application of DevOps practices to ML pipelines—often referred to as MLOps—presents both unique challenges and significant benefits. MLOps seeks to streamline the ML model lifecycle, from data collection and model training to deployment and monitoring, applying the principles of DevOps to ensure that ML models are developed and deployed efficiently and reliably. However, the inherent complexity of ML workloads, coupled with the need for specialized hardware and software environments, poses distinct obstacles. Despite these challenges, integrating DevOps practices into ML pipelines promises to enhance collaboration between data scientists and operations teams, improve model quality through continuous testing and integration, and accelerate the delivery of innovative ML-driven applications.
The Intersection of DevOps and Machine Learning
MLOps, or Machine Learning Operations, represents a holistic approach that amalgamates DevOps principles with machine learning (ML) workflows to streamline the development, deployment, and maintenance of ML models. It embodies the core objectives of DevOps—such as collaboration, automation, and continuous improvement—within the context of ML projects. By incorporating practices like continuous integration (CI), continuous delivery (CD), and automated monitoring into ML pipelines, MLOps facilitates a more structured and efficient lifecycle management of ML models from experimentation to production.

The integration of DevOps practices into ML workflows serves several critical functions that cannot be ignored. Firstly, it encourages a seamless collaboration between data scientists, developers, and operations teams, which is imperative for the creation and deployment of ML models. Secondly, MLOps emphasizes efficiency throughout the ML model lifecycle, automating repetitive tasks such as data preprocessing and model training, which not only accelerates the development process but also reduces the potential for human error.
Moreover, reliability is a cornerstone of MLOps, and it is crucial to ensure that models are not only accurate but also perform consistently under varying conditions and can be easily updated or rolled back as necessary. Reliability also pertains to the data feeding into these models; it must be clean, relevant, and reflective of the current environment to maintain the integrity of the model's predictions.
MLOps not only integrates DevOps practices into ML workflows but also enhances the collaboration, efficiency, and reliability of ML projects. By adopting an MLOps framework, organizations can better manage the complexities associated with developing and deploying machine learning models, ultimately leading to more innovative and robust solutions. It is essential to take MLOps seriously to ensure the success of ML projects and gain a competitive advantage in the market.
Machine Learning Operations Lifecycle
The MLOps (Machine Learning Operations) lifecycle is a set of practices that aims to deploy and maintain machine learning models in production reliably and efficiently. The MLOps lifecycle is similar to the DevOps lifecycle but is tailored specifically to machine learning models.
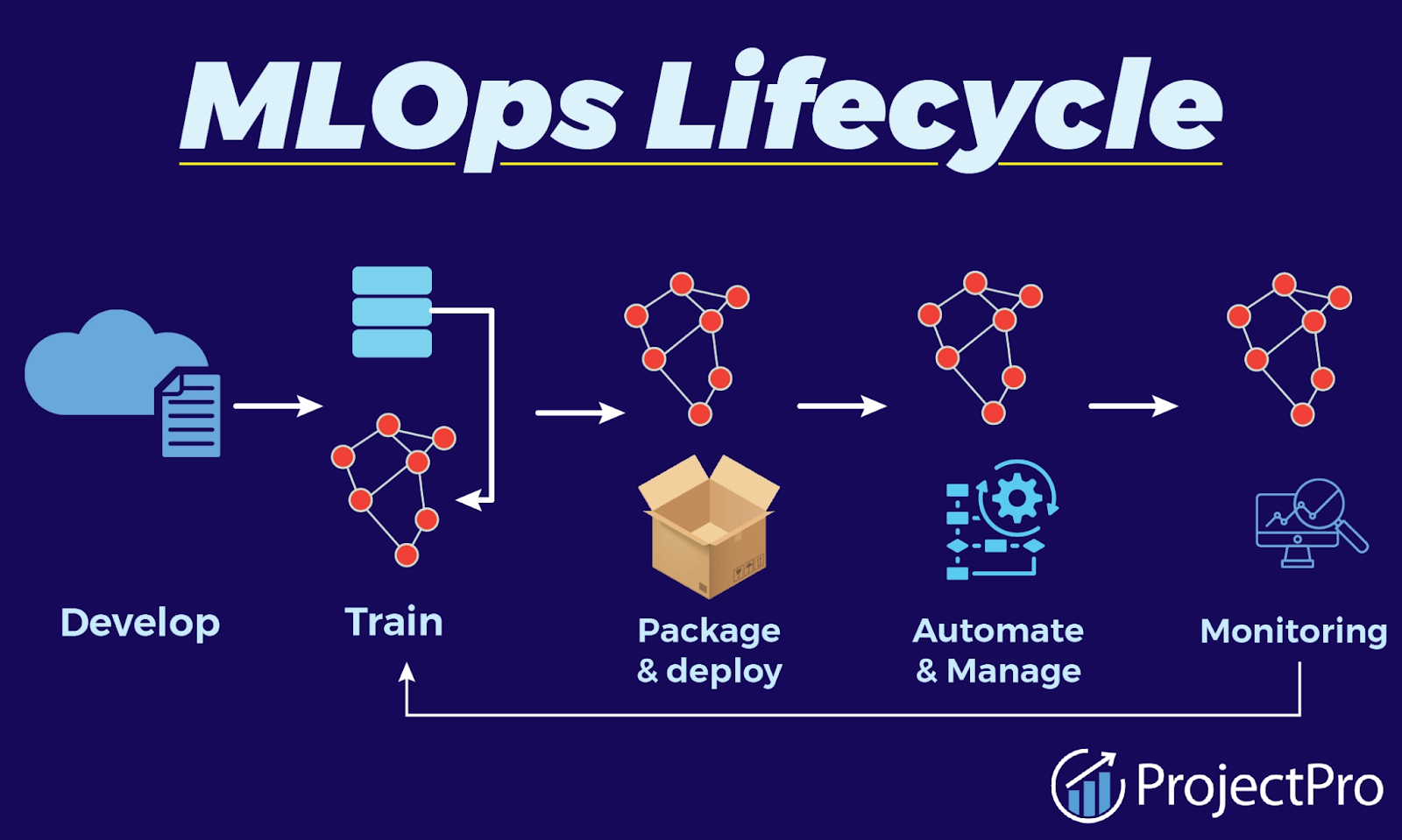
Let’s break down the lifecycle using the illustration above:
- Develop: This stage involves the creation of machine learning models. It includes defining the problem, collecting and preprocessing data, feature engineering, and selecting algorithms.
- Train: Once the model is developed, the next step is to train it using datasets. This process involves feeding data into the model to help it learn and adjust its weights and parameters. The training phase is iterative and can involve tuning the model for better accuracy and performance.
- Package & Deploy: After the model is trained and evaluated, it is packaged for deployment. This means preparing the model to be integrated into the production environment, which could include containerization or conversion to a format compatible with the production systems. Deploying the model makes it available for end-users or applications to provide predictions.
- Automate & Manage: Automation is about creating workflows that automatically retrain, update, and deploy models with minimal human intervention. Management includes versioning of models, scaling the deployment according to the load, and handling dependencies.
- Monitoring: The final step in the lifecycle is to monitor the deployed models. This includes tracking their performance, checking for data drift, and model decay, and ensuring they are providing accurate predictions. If the performance drops, the model may need to be retrained with new data.
Each of these stages can start a loop, as shown in the illustration. For instance, the monitoring stage can lead to further training, indicating an iterative process of model improvement if the model's performance degrades over time. This lifecycle helps maintain the health and usefulness of machine learning models once they are deployed in real-world settings.
Key Challenges in ML Pipelines
Machine Learning (ML) pipelines are crucial for the streamlined development and deployment of ML models. However, they are not without their challenges. Common hurdles such as data versioning, model reproducibility, and deployment complexities can significantly impede the progress and effectiveness of ML projects.
- Data Versioning: One of the first challenges in ML pipelines is managing and tracking the versions of datasets used for training and testing models. Given that ML models are only as good as the data they are trained on, maintaining a consistent and version-controlled dataset is crucial for the accuracy and reliability of the model. Without proper data versioning practices, it becomes difficult to reproduce results or understand the impact of data changes on model performance.
- Model Reproducibility: Reproducing the exact conditions under which a model was trained is often challenging due to the myriad of factors involved, including data version, model parameters, and environment settings. This reproducibility crisis can lead to discrepancies in model performance when moving from development to production environments.
- Deployment Complexities: Deploying ML models involves more than just placing a static piece of software into a production environment. It requires careful consideration of how the model will consume data in real time, interact with existing systems, and how it will be monitored and updated. These complexities necessitate a robust framework to manage deployment efficiently.
Addressing Challenges with DevOps Principles
The integration of DevOps principles into ML pipelines, a practice known as MLOps, offers solutions to these challenges:
- For Data Versioning: DevOps principles advocate for rigorous version control not just for code but for all artifacts involved in the development process, including data. Tools and practices that enable data versioning allow teams to track changes, experiment confidently, and roll back to earlier versions if needed, thereby ensuring data integrity and consistency.
- Enhancing Model Reproducibility: The CI/CD pipelines, central to DevOps, can be extended to ML workflows to ensure models are built, tested, and deployed consistently. By automating these pipelines, teams can document and reproduce the exact conditions under which a model was trained and deployed, including the specific data version, model parameters, and environment configurations.
- Simplifying Deployment Complexities: DevOps principles emphasize automation, monitoring, and continuous improvement—key elements in simplifying the deployment of ML models. Automation tools can streamline the deployment process, while continuous monitoring ensures the model's performance is consistently tracked. Additionally, a culture of continuous improvement encourages regular updates and optimizations to the model, making the deployment process more agile and responsive to changes.
By adopting DevOps principles, organizations can tackle the inherent challenges of ML pipelines, leading to improved productivity, enhanced model quality, and more reliable deployments. This strategic integration not only simplifies the complexities of ML workflows but also accelerates the journey from data to valuable insights.
Best Practices for Integrating DevOps in ML Pipelines
Integrating DevOps practices into Machine Learning (ML) pipelines can significantly enhance the efficiency, reliability, and scalability of ML projects. Below are some of the best practices that can facilitate this integration, ensuring smoother workflows and better outcomes.
Continuous Integration and Continuous Deployment (CI/CD) for ML
CI/CD, the backbone of DevOps, can be tailored for ML workflows to automate the testing, integration, and deployment of ML models. This involves:
- Automated Testing: Implementing automated testing for ML models is crucial. This includes unit tests for code, integration tests for data pipelines, and model validation tests to assess performance against predefined metrics.
- Version Control: Ensuring both code and data are version-controlled allows for tracking changes and managing different versions of models effectively.
- Automated Deployment: Automating the deployment process helps in the seamless transition of ML models from development to production, minimizing human error and deployment time.
Adapting CI/CD for ML requires tools that can handle the specificities of ML workflows, such as data versioning, model testing, and deployment to various environments.
Infrastructure as Code (IaC)
IaC is a key practice in DevOps that involves managing and provisioning infrastructure through code rather than manual processes. For ML workflows, IaC ensures:
- Consistency: By codifying the environment setups, IaC guarantees that the infrastructure is consistent across development, testing, and production environments, reducing "it works on my machine" issues.
- Scalability: IaC makes it easier to scale ML workflows by allowing infrastructure to be provisioned automatically as needed, ensuring resources are available for training and inference without manual intervention.
- Reproducibility: With IaC, ML environments can be replicated exactly, aiding in model reproducibility and simplifying the process of setting up new environments.
Tools like Terraform, Ansible, and Kubernetes can be used to implement IaC in ML pipelines, managing everything from data storage to compute resources.
Monitoring and Logging
Monitoring and logging are vital for maintaining the performance and reliability of ML models in production:
- Performance Tracking: Continuously monitoring model performance against key metrics helps in identifying when a model might be degrading or needs retraining.
- Anomaly Detection: Logging system metrics and model predictions can assist in detecting anomalies or errors in real-time, facilitating quick responses to issues.
- Feedback Loops: Implementing monitoring and logging enables feedback loops that can inform future model improvements and deployments.
Tools such as Prometheus for monitoring and Elasticsearch, Logstash, and Kibana (ELK) for logging are commonly used to implement these practices in ML pipelines.
Collaboration and Communication
Effective collaboration and communication between data scientists, ML engineers, and DevOps teams are critical for the successful integration of DevOps in ML pipelines:
- Shared Tools: Using shared platforms for version control (e.g., Git), project management (e.g., Jira), and communication (e.g., Slack) can help bridge the gap between teams.
- Cross-functional Training: Providing opportunities for cross-training can help team members understand each other's roles and challenges better, fostering empathy and collaboration.
- Documentation: Maintaining thorough documentation of data, models, and deployment processes ensures that knowledge is accessible to all team members, aiding in collaboration and knowledge transfer.
Implementing these best practices requires a commitment to adopting new tools and methodologies and fostering a culture of continuous improvement and learning. By integrating DevOps practices into ML pipelines, organizations can not only streamline their ML workflows but also enhance the quality and impact of their ML initiatives.
Tools and Technologies for DevOps in ML
MLOps is facilitated by a variety of tools and technologies designed to streamline the development, deployment, and maintenance of ML models. Below is an overview of some of the popular tools and platforms that are pivotal in adopting DevOps practices in ML projects.
- Docker: Docker is a platform for developing, shipping, and running applications in containers. Containers package up code and all its dependencies so the application runs quickly and reliably from one computing environment to another. In the context of ML, Docker ensures consistency across different stages of the ML lifecycle, from experimentation to production, minimizing the "it works on my machine" problem.
- Kubernetes: Kubernetes is an open-source system for automating deployment, scaling, and management of containerized applications. It is particularly useful for deploying and managing ML models at scale, offering features like auto-scaling, rollouts and rollbacks, and load balancing. Kubernetes can manage complex ML workflows across diverse environments, ensuring high availability and efficient use of resources.
- MLflow: MLflow is an open-source platform to manage the ML lifecycle, including experimentation, reproducibility, and deployment. It offers four primary features: tracking experiments to record and compare parameters and results, packaging ML code in a reusable and reproducible form, managing and deploying models from diverse ML libraries to a variety of platforms, and serving models. MLflow is designed to work with any ML library, algorithm, deployment tool, or language.
- TensorFlow Extended (TFX): TensorFlow Extended (TFX) is an end-to-end platform designed to deploy production-ready ML pipelines. It provides a comprehensive set of components and libraries that support the deployment of robust, scalable, and continuously trained ML models. TFX covers a wide range of tasks needed for ML workflows, from data validation and preprocessing to model serving and monitoring.
Selecting the Right Tools
When selecting tools for integrating DevOps in ML projects, consider the following factors:
- Project Complexity and Scale: Larger, more complex projects may benefit from the scalability and robustness of Kubernetes, while smaller projects could leverage simpler container management tools.
- Team Expertise: Choose tools that align with the team’s existing expertise or be prepared to invest in training. For instance, if your team is already familiar with TensorFlow for model development, integrating TensorFlow Extended (TFX) for MLOps might be a natural choice.
- Ecosystem Compatibility: Consider how well the tool integrates with your existing development, data processing, and deployment ecosystem. Tools like MLflow offer flexibility and can be easily integrated with various ML libraries and deployment environments.
- Open Source vs. Proprietary: Open-source tools like Kubernetes and MLflow offer flexibility and community support but may require more setup and maintenance. Proprietary platforms may offer more out-of-the-box functionality and support, but at a cost.
Selecting the right set of tools is critical for the successful implementation of DevOps practices in ML projects. By carefully evaluating project needs, team expertise, and tool compatibility, organizations can create a robust MLOps framework that enhances productivity, improves model quality, and accelerates innovation.
Conclusion
Adopting these best practices in your ML projects is not just a strategic move for enhanced productivity; it is a transformative approach that can lead to superior model performance, greater scalability, and ultimately, better business outcomes. As the field of ML continues to evolve, the integration of DevOps practices remains a critical element for staying competitive and achieving success in AI-driven initiatives.
We invite our readers to share their experiences or pose questions regarding the application of DevOps practices in ML workflows. Your insights and inquiries not only contribute to the knowledge base but also foster a community of learning and innovation. Whether you are just starting on your MLOps journey or looking to refine your existing processes, collective wisdom and shared experiences can provide valuable guidance and inspiration.
Akava would love to help your organization adapt, evolve and innovate your modernization initiatives. If you’re looking to discuss, strategize or implement any of these processes, reach out to bd@akava.io and reference this post.