
Table of Contents
An in-depth exploration of serverless databases, their architecture and best practices.
Modern application architectures are evolving quickly, moving away from traditional monoliths to more flexible microservices and now to completely serverless environments. As developers aim to build applications that are faster, scalable, and more reliable, a new wave of tools is emerging to support this transformation. Among these tools, serverless databases are becoming essential for cloud-native applications, but what does “serverless” really mean when it comes to data storage, and why should developers take notice?
When we say "serverless," it doesn’t mean there are no servers involved; rather, it means that developers don’t have to worry about provisioning, scaling, or managing them. With serverless architectures, the underlying infrastructure is abstracted away, allowing developers to focus on what matters: creating great application features, enhancing user experience, and delivering business value without getting bogged down by operational tasks.
Unlike traditional databases, where developers have to manage things like provisioning compute power, determining capacity, and handling backups, serverless databases take care of all that complexity automatically. They provide features like auto-scaling, pay-as-you-go billing, and easy integration into modern, event-driven systems. This leads to a more agile development process, with a database layer that works seamlessly with how contemporary applications are built and run.
As the demands of applications grow and users expect instant, always-on experiences, serverless databases offer the scalability and flexibility necessary to meet those expectations, without the usual operational headaches or cost inefficiencies. This article will dive into the basics of serverless databases, compare them to traditional models, and illustrate why adopting a serverless approach could be a game-changer for your next application.
What Is a Serverless Database?
Serverless databases are revolutionising the developer experience by providing a seamless, hands-off approach to data management. Imagine a world where you don’t have to worry about setting up, maintaining, or scaling database servers. With serverless computing, that’s exactly what you get! The cloud providers take care of all the technical heavy lifting, allowing teams to concentrate on what matters: delivering features and creating amazing user experiences.
At the heart of serverless databases are three essential features: they automatically scale with your needs, charge you only for what you use, and offer a fully managed setup. Unlike traditional or even managed databases, there’s no need to predict how much capacity you’ll need or to set manual scaling rules. Instead, resources adjust in real-time based on your application’s activity, so you're only paying for the compute time, storage, or I/O operations you require, no more wasting money on unused resources.
Internally, serverless databases often separate compute from storage, which allows for greater scalability and efficiency. The compute resources can be temporary, spinning up just long enough to process a query, while the storage remains persistent and secure. Thanks to this structure, tasks like backups, updates, and failovers are all managed by the platform, eliminating the need for manual intervention.
Despite the name “serverless,” there’s no actual absence of servers; they just aren’t something you have to manage anymore. Some people might think “serverless” means it’s simpler or less capable, but that’s a misconception. In reality, serverless databases often deliver better service level agreements (SLAs), lower latency, and more advanced scalability features compared to traditional databases. So, while “serverless” might sound like a buzzword, it’s really about rethinking database functionality in a fast-paced world where speed, reliability, and developer efficiency are essential.
Core Architectures & Operational Models
Modern serverless databases adopt a decoupled architecture that separates compute, storage, and orchestration layers. This modular design enables elastic scaling, high durability, and low-latency query execution—while abstracting away operational complexity from developers. Let’s unpack how these systems operate behind the scenes.
Layered Architecture Overview
A serverless database typically comprises three functional layers:
Storage Layer
At the foundation lies a highly durable and distributed data storage layer. This is where all persistent data resides—replicated, versioned, and checkpointed across zones or regions for fault tolerance. It is write-optimized and independent of query processing.Database Processing Layer
Above the storage layer sits a pool of stateless compute instances. These are activated on demand to process queries. The pool consists of:Active databases handling live traffic
Standby databases that can be promoted rapidly during traffic spikes or failover
Because this layer is decoupled from storage, it can scale horizontally without data rebalancing.
Proxy & Control Plane Layer
A lightweight proxy tier orchestrates communication between clients and database instances, routing queries intelligently based on availability and workload. Behind this, a control plane handles autoscaling, access policies, query planning, and metadata distribution.
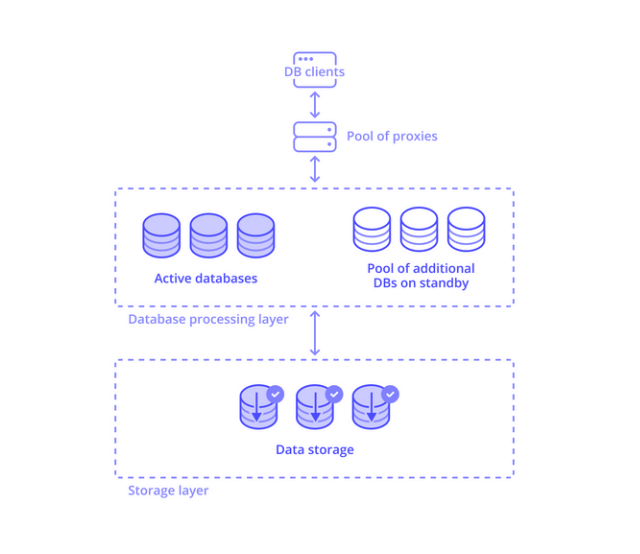
Layer | Function |
Proxy Layer | Forwards client requests to appropriate compute resources |
Database Processing Layer | Executes queries using stateless, autoscaling compute |
Storage Layer | Stores durable, replicated, and consistent data |
Scaling Strategies: Reactive vs. Pre-Provisioned Capacity
Serverless databases are built to scale automatically based on demand patterns. Two primary strategies are commonly implemented:
Scaling Model | Description | Best For |
Reactive (On-Demand) | Allocates compute dynamically when queries arrive | Spiky, unpredictable workloads |
Pre-Warmed Pools | Keeps a pool of ready-to-serve compute nodes online | Latency-sensitive applications |
Some systems also allow burst scaling, temporarily expanding beyond provisioned limits to absorb transient surges without sacrificing performance.
Tunable Consistency & Durability
Decoupling compute from storage introduces a trade-off between consistency guarantees and latency/performance. Most serverless databases offer one of the following models:
Model | Consistency | Durability | Use Case |
Eventual Consistency | Data may lag across replicas | High (via multi-zone replication) | Real-time analytics, IoT, log ingestion |
Strong Consistency | Synchronous updates with read-after-write guarantees | High (via WALs, consensus protocols) | Transactional systems, OLTP workloads |
Some platforms give developers the flexibility to adjust consistency based on their needs, choosing between speed and accuracy for each query.
This flexible and organized structure allows serverless databases to provide the advantages of cloud computing, like easy scalability, low management hassle, and good fault tolerance. All of this happens behind the scenes, so developers can concentrate on building their applications rather than dealing with complicated infrastructure details.
Major Serverless Database Offerings & Feature Comparison
As serverless computing continues to evolve, various cloud providers and newer companies have rolled out a variety of serverless database options tailored to meet different use cases, workloads, and the preferences of developers. While these databases all take care of infrastructure management and offer elastic scaling, they vary significantly in their underlying architecture, features, and the overall experience they provide to developers. Below, you’ll find an overview of the key players in the serverless database landscape, along with a feature comparison matrix to help you see how their offerings stack up against one another.
AWS Aurora Serverless v2 vs. DynamoDB On-Demand
Aurora Serverless v2 is a versatile relational database that works with MySQL and PostgreSQL. Its smart design allows it to automatically scale up or down based on your application's needs, all while ensuring that transactions remain reliable and consistent.
On the other hand, DynamoDB On-Demand is a NoSQL database that excels at handling key-value and document storage. It's built for speed, delivering high performance even when your workload varies. You don't have to worry about capacity planning, and features like point-in-time recovery simplify data management. It plays nicely with event-driven applications, making it a great choice for dynamic environments.
Feature | Aurora Serverless v2 | DynamoDB On-Demand |
Data Model | Relational (SQL) | NoSQL (key-value/document) |
Scaling | Fine-grained compute scaling | Instant, automatic throughput scaling |
Transactions | Full ACID | ACID for single-table only |
Latency | Sub-second | Single-digit milliseconds |
Use Cases | Web apps, reporting, analytics | IoT, gaming, real-time APIs |
Azure Cosmos DB Serverless vs. Google Cloud Firestore
Cosmos DB Serverless is a flexible, globally available NoSQL database that's designed to scale with your needs. With a serverless pricing model, you only pay for the reads, writes, and storage you use. It supports multiple APIs, including MongoDB, Cassandra, SQL, and Gremlin, making it versatile for different applications.
On the other hand, Google Cloud Firestore is a powerful document-based NoSQL database that focuses on scalability. It offers features like offline synchronization and strong consistency, which ensure your data is reliable and readily available. Plus, it integrates seamlessly with Firebase, making it an excellent choice for developers building applications that require real-time data synchronization.
Feature | Azure Cosmos DB Serverless | Google Cloud Firestore |
Data Model | Multi-model (document, graph, key-value) | Document-based |
Global Distribution | Yes (multi-region, active-active) | Yes (multi-region) |
Consistency Levels | 5 tunable options | Strong and eventual |
SDKs & Tooling | Rich cross-API support | Firebase-native, mobile optimized |
Use Cases | E-commerce, social apps, IoT | Mobile apps, real-time collaboration |
Open-Source & Emerging Options
Several independent and open-source solutions are pushing the boundaries of serverless data management with innovative features.
PlanetScale: Built on Vitess and MySQL, making it a powerful choice for developers. It offers features like horizontal sharding, which helps manage large amounts of data, and allows for schema changes without downtime. Also, its Git-like deployment workflow makes it easy to handle updates. It's a great option for those who want the benefits of a relational database without the usual operational headaches.
FaunaDB: A powerful, worldwide document-relational database that makes it easy to work with data thanks to its built-in support for GraphQL and FQL. It's designed to be secure and fast, providing global access without the overhead of traditional servers. It also follows ACID principles, ensuring your transactions are reliable and consistent. Overall, Fauna is about simplifying your database needs while keeping everything secure and efficient.
Feature | PlanetScale | FaunaDB |
Query Language | SQL (MySQL-compatible) | FQL / GraphQL |
ACID Transactions | Yes | Yes |
Global Distribution | Yes (read replicas) | Yes (multi-region active-active) |
Developer Experience | GitOps workflows, CLI-first | Serverless-native, API-driven |
Use Cases | SaaS, financial tech, scale-up apps | JAMstack, global APIs, event-driven apps |
Serverless databases offer a lot of flexibility, supporting both relational and NoSQL styles, which makes them suitable for various applications from real-time chat apps to multi-tenant SaaS solutions. When deciding which one to use, consider what matters most to you: how consistent you need your data to be, what data model fits your needs, the performance requirements of your app, and the workflow that your development team prefers.
Design Considerations
Designing applications with serverless databases changes how we approach things. Instead of spending lots of time planning out rigid infrastructure, we need to adopt a more flexible way of thinking that focuses on how we use the system. While serverless solutions take care of much of the operational complexity behind the scenes, it's still crucial for developers and architects to be mindful of their decisions, like how they structure queries, design their database schema, and set up access patterns. These choices can significantly affect things like latency, costs, and security. Serverless databases can scale dramatically, but to get the most out of them, we need to be thoughtful in our design to ensure everything runs smoothly and surprises are kept to a minimum.
Query and Schema Patterns for Predictable Latency
Serverless databases, whether they're relational or NoSQL, can struggle with inefficient queries and poorly organized data. Because the computing resources in these systems are temporary and don’t hold onto any state, how long it takes to run a query is closely linked to how the data is accessed. In other words, if your queries aren’t optimized or your data isn’t structured well, you could end up with slow performance.
Best practices include:
Denormalize when appropriate: In NoSQL models like DynamoDB or Firestore, flattening data into access-optimized shapes reduces joins and round-trips.
Use partition keys strategically: For consistent performance under load, especially in systems like Cosmos DB and DynamoDB.
Avoid full-table scans: Prefer indexed queries and targeted reads.
Batch operations: Minimize network calls and reduce cold-start amplification by bundling writes or reads.
Cost-Control Strategies
Serverless databases follow a pay-per-use model—great for agility, but dangerous without guardrails. Cost visibility and predictability require proactive planning.
Strategy | Benefit |
Throttling & rate limits | Prevents runaway costs from high-traffic anomalies |
Scheduled warm-up jobs | Reduces cold-start delays for predictable traffic |
Usage forecasts & budgeting tools | Enables capacity planning and alerting |
Request batching & pagination | Lowers I/O operations and improves throughput |
Serverless doesn’t mean costless—your architecture should optimize for both scale and efficiency.
Security at Scale
Security is foundational, not optional. Serverless databases offer deep integrations with identity and access management (IAM) frameworks, encryption tools, and network controls.
Key security practices include:
IAM-based access control: Integrate cloud IAM roles (e.g., AWS IAM, Azure RBAC) with fine-grained database permissions.
Encryption in transit and at rest: Default in most serverless DBs, but always verify compliance with your security policy.
VPC and private endpoints: Keep traffic off the public internet with network isolation where available.
Audit logging: Track access patterns, schema changes, and privileged user activity for compliance and forensics.
Monitoring and Observability
Even with automated operations, visibility is crucial. Serverless databases integrate with modern observability stacks to help diagnose latency spikes, cold starts, and cost anomalies.
Monitoring Layer | Examples |
Cloud-native metrics | CloudWatch, Azure Monitor, Google Cloud Operations |
Application Performance Monitoring (APM)** | Datadog, New Relic, OpenTelemetry |
Query performance insights | Query planners, index usage, slow log analysis |
To really understand how your applications are performing, it’s essential to link app latency with the metrics from your backend databases. This visibility should be part of your continuous integration and continuous deployment (CI/CD) process.
By leveraging serverless databases, you can enjoy the benefits of enterprise-level functionality while still maintaining the agility of a startup. This means being mindful of performance, costs, and built-in security from the start. The trick is to recognize the trade-offs involved and to design your systems with scalability, responsiveness, and resilience in mind.
Conclusion
Serverless databases are transforming how modern applications handle data, offering high scalability, ease of use, and cost savings. By removing infrastructure concerns, developers can focus on building and refining their applications without managing servers.
The benefits include automatic scaling, usage-based billing, lower operational overhead, and global accessibility. However, there are trade-offs to consider, such as query efficiency, schema design, and consistency guarantees. While serverless solutions simplify some things, they also require thoughtful design and observability.
When choosing a serverless database, consider your application's consistency needs, access patterns, data model, and latency requirements. For relational use cases with SQL workflows, Aurora Serverless v2 or PlanetScale are excellent options. For real-time applications, Firestore, DynamoDB, or FaunaDB may be more suitable. Cosmos DB or FaunaDB work well for multi-model or globally distributed apps.
To find the right fit, prototype and benchmark your options. Start small, use real workload data, and monitor performance under load. Although serverless databases aren’t one-size-fits-all, they can enhance agility and efficiency when thoughtfully integrated. As cloud-native practices advance, serverless databases will play an increasingly vital role in building effective and accessible systems. Now is the time to explore and reshape your data strategy!
Akava would love to help your organization adapt, evolve and innovate your modernization initiatives. If you’re looking to discuss, strategize or implement any of these processes, reach out to bd@akava.io and reference this post.