Table of Contents
- Cold Starts: The Tax on Serverless
- Cold Start Mitigation Strategies
- Cost Economics: When Serverless Saves and When It Does Not
- Concurrency Limits: The Invisible Ceiling
- Observability: The Distributed Debugging Problem
- Vendor Lock-In: A Measured Assessment
- The AI Dimension: Serverless GPUs and Inference Workloads
- Strategic Guidance for Production Serverless
- Conclusion
A technically grounded analysis with current benchmarks, cost models, and operational lessons
When serverless first entered the mainstream, it carried a near-utopian promise: infinite scale without infrastructure management. Developers could deploy code without provisioning servers, operations teams could shed entire classes of toil, and businesses would only pay for the exact compute they consumed. With the launch of AWS Lambda and the rapid expansion of managed event sources, serverless quickly became a centerpiece of the cloud-native narrative.
But as teams moved beyond prototypes and into large-scale, long-running production systems, the story became more nuanced. Serverless excels in specific domains, but introduces trade-offs that are not always apparent at first glance. This article cuts through the hype grounded in current benchmark data, real pricing models, and production war stories to examine where serverless truly shines, where it struggles at scale, and the tactical decisions teams face when moving from early adoption to production reality.
Cold Starts: The Tax on Serverless
Cold starts remain the top complaint about serverless in 2025. They occur when AWS Lambda (or any FaaS platform) must provision a new execution environment because no warm instance is available, typically after a period of inactivity (5–45 minutes), during a rapid scaling event, or after a code deployment.
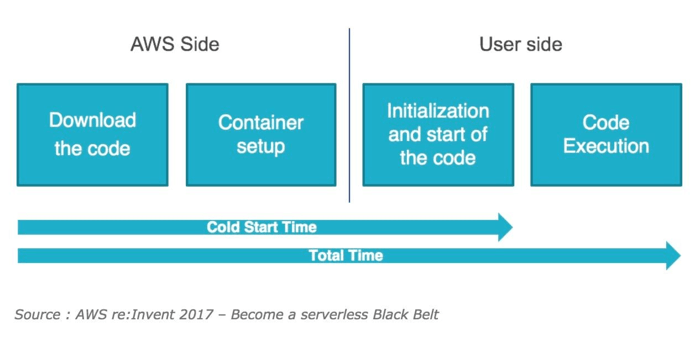
Anatomy of a Cold Start
A cold start consists of several sequential phases, each adding measurable latency:
Container provisioning: Lambda allocates compute resources (Firecracker microVMs) based on the function's configured memory.
Runtime initialization: The language runtime (Node.js, Python, JVM, etc.) is loaded and started.
Code loading: Lambda downloads and unpacks the function code from S3 or ECR.
Initialization code: Any code outside the handler DB connections, SDK instantiation, and config loading runs to completion before the first request is served.
The INIT phase is where all cold start latency accumulates. Critically, as of August 2025, AWS began billing for the Lambda INIT phase at the same rate as invocation duration. For functions with heavy startup logic, this shift can increase Lambda spend by 10–50%.
Cold Start Benchmarks by Runtime (2024–2025)
Cold start times vary dramatically by runtime, package size, and infrastructure configuration. Key findings from recent benchmarks:
Runtime | Typical Cold Start (managed) | Docker-based Cold Start | Notes |
Node.js (managed) | ~200–400 ms | ~600–1,200 ms | Package size is the dominant factor |
Python (managed) | ~200–500 ms | ~700–1,400 ms | Import-heavy dependencies add latency |
Java + Spring Boot | ~3,000–6,000 ms | ~2,000–5,000 ms | JVM + framework init; SnapStart helps |
Java + SnapStart | ~200–600 ms | N/A | 4.3x reduction from 6.1s to 1.4s |
Deno (Docker) | Fastest of JS runtimes | Lowest p99 in JS | Benchmarked against Node, Bun |
Rust / Go | ~50–200 ms | ~100–400 ms | Compiled binaries with minimal runtime overhead |
Source: Deno AWS Lambda cold start benchmarks (2024); AWS SnapStart blog (April 2025); EdgeDelta cold start analysis (December 2025).
Key insight: AWS reports that fewer than 1% of Lambda invocations experience a cold start. However, this aggregate figure masks the tail-latency impact. For a function receiving 1,000 req/s with a 500 ms cold start, the average latency impact is only ~5 ms, but p99 latency can be seconds. The question is not whether cold starts happen, but whether your SLA tolerates the tail.
Cold Start Mitigation Strategies
There are three principal strategies, each with distinct tradeoffs:

1. Provisioned Concurrency: Keeps execution environments pre-initialized and warm. Eliminates cold starts for the configured capacity. Cost: approximately $220/month for 5 instances at 1 GB memory in us-east-1, billed hourly regardless of usage. Use Application Auto Scaling to adjust provisioned concurrency on schedule or utilization.
2. SnapStart (Java): Introduced at re:Invent 2022, SnapStart snapshots the initialized execution environment and restores it on subsequent invocations. Reduces Spring Boot cold starts from ~6.1s to ~1.4s, a 4.3x improvement. Supports invoke priming (executing critical endpoints during snapshot creation) and class priming (preloading classes without business logic side effects).
3. Code-level optimization: Package size is one of the strongest predictors of cold start duration. Keep Node.js packages under 1 MB using bundlers with tree-shaking (Webpack, esbuild). Use Lambda Layers for shared dependencies. Prefer ARM64 architecture, it consistently reduces cold starts for medium-to-large functions. Move expensive initialization (DB connections, large object setup) to lazy initialization patterns inside the handler.
Warning: Many teams overspend on mitigation. It is not uncommon to spend $500/month on provisioned concurrency to solve what is effectively a $50 problem. Profile your cold start rate and p99 impact before committing to provisioned capacity.
Cost Economics: When Serverless Saves and When It Does Not
The pay-per-execution model is compelling in theory, but the economics shift significantly as workloads grow. Understanding the tipping points is essential for making sound architectural decisions.
How Lambda Billing Actually Works
Lambda billing has three dimensions: request count ($0.20 per million), duration in GB-seconds ($0.0000166667 per GB-second), and, as of August 2025, INIT duration is now billed at the same rate. Memory allocation directly controls CPU power (1 vCPU is allocated at 1,792 MB), meaning memory tuning affects both performance and cost simultaneously.
One nuance often missed: Lambda bills in 1 ms increments (down from 100 ms in 2021), meaning short functions under 50 ms can see significant cost differences across runtimes.
Serverless vs. Container Cost Tipping Points
A concrete model (us-east-1, June 2025 pricing) illustrates when the cost equation flips:
Scenario | Serverless Cost | Container (EKS) Cost | Winner |
Low-traffic API (< 1M req/mo) | ~$5–15/mo | ~$70–150/mo (idle EKS nodes) | Serverless |
Spiky traffic (10x daily peak) | ~$40–80/mo | ~$120–200/mo (over-provisioned) | Serverless |
Steady microservice (65% CPU, 24/7) | ~$450/mo | ~$110/mo (ARM Spot EKS) | Containers 4x cheaper |
Video transcoding (3 GB, 90s each) | ~$4.50 per 1,000 runs | ~$1.10 per 1,000 (Fargate ARM) | Containers |
Event-driven ETL (irregular) | Pay only on execution | Always-on baseline cost | Serverless |
The tipping point in CPU-bound scenarios: if your average CPU load stays below ~20% over a 24/7 window with predictable traffic, containers become cost-inefficient. Above that threshold with sustained load, serverless per-invocation billing typically exceeds container reservation costs.
Hidden Cost Multipliers at Scale
Several costs compound rapidly at scale and are frequently underestimated in initial projections:
Networking and egress: Cross-AZ data transfer at $0.045/GB compounds significantly in chatty microservice architectures. Serverless functions in VPCs can incur NAT gateway charges that exceed compute costs.
CloudWatch Logs: At scale, observability itself becomes a cost center. Teams processing 500 GB/month in Lambda logs face ~$250/month in CloudWatch charges alone. Telemetry pipelines (e.g., Edge Delta) can reduce this volume by 60–80% through pre-aggregation and filtering.
Orchestration overhead: Step Functions charges $0.025 per 1,000 state transitions. Complex workflows with many steps at high volume can generate surprising costs.
Memory over-allocation: Because CPU scales linearly with memory in Lambda, over-allocating memory wastes both compute and budget. Use Lambda Power Tuning (open source) to find the optimal memory setting that minimizes cost*duration.
FinOps lesson: Model costs based on concurrency and execution duration, not just request volume. A function averaging 2 seconds at 1 GB memory, invoked 10 million times per month, costs ~$333 in duration charges alone, before requests, egress, or logging.
Concurrency Limits: The Invisible Ceiling
One of the least-discussed production risks of serverless at scale is account-level concurrency limits. These are hard ceilings that, when breached, cause silent request failures and 429 throttling errors.
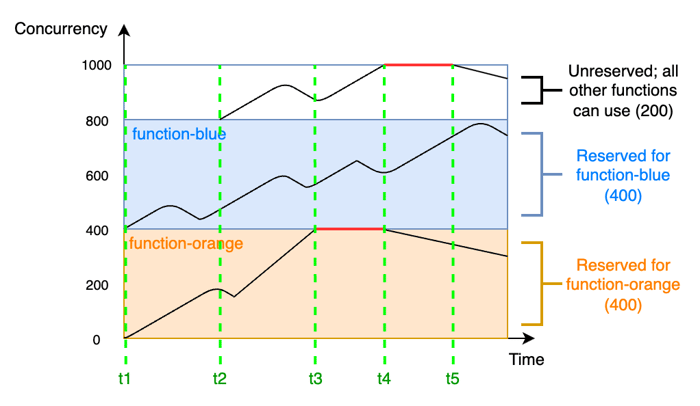
How Concurrency and Throttling Work
By default, each AWS account has a limit of 1,000 concurrent executions across all Lambda functions in a region. This is not a rate limit; it is a limit on simultaneous in-flight invocations at any given moment.
The relationship between concurrency and throughput depends on function duration. A function averaging 1 second duration at 1,000 concurrency achieves 1,000 TPS. The same function at 100 ms duration achieves 10,000 TPS. Shorter functions extract dramatically more throughput from the same concurrency budget.
When the concurrency limit is reached:
Synchronous invocations (API Gateway, SDK on-demand): Return HTTP 429 immediately. No retry.
Asynchronous invocations (S3, SNS): Lambda retries twice automatically, then routes to a dead-letter queue if configured.
Queue-based (SQS): Lambda holds messages and retries until the queue retention period expires.
Concurrency Management Strategies
Reserved concurrency: Dedicates a fixed number of concurrent executions to a specific function, preventing other functions from consuming it. Also acts as a hard cap, useful for protecting downstream dependencies (databases, third-party APIs) from being overwhelmed.
Provisioned concurrency: Keeps warm instances ready. Unlike reserved concurrency, it also eliminates cold starts. Best for latency-sensitive functions with predictable peak load patterns.
SQS maximum concurrency: Introduced in 2023, allows setting a maximum concurrency per SQS event source mapping (2–1,000), independent of function-level reserved concurrency. Prevents a single queue consumer from consuming the entire account concurrency budget during a spike.
Production war story pattern: A team migrates a monolith to serverless microservices across 30 Lambda functions, each sharing the 1,000 concurrency pool. A marketing campaign drives a 20x traffic spike. A single high-traffic function exhausts the account concurrency, throttling all other functions region-wide. The fix: reserve concurrency per function based on traffic profiling, and request a quota increase proactively before launch.
Observability: The Distributed Debugging Problem
Serverless systems distribute logic across dozens or hundreds of ephemeral functions. Traditional log-based debugging is insufficient. A single user request may traverse API Gateway, Lambda, SQS, another Lambda, DynamoDB, and a third-party API, with each hop generating independent telemetry in isolated contexts.
The Three Pillars Applied to Serverless
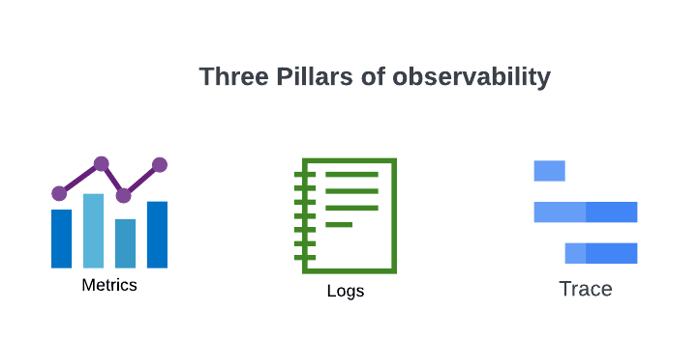
Logs: Structured JSON logging is table stakes. CloudWatch Logs Insights enables SQL-like querying, but at high volumes, costs, and query latency become problematic. Filter patterns and log groups per function make it hard to correlate across a full request flow.
Metrics: Lambda emits standard CloudWatch metrics (Invocations, Errors, Duration, Throttles, ConcurrentExecutions). Custom metrics via EMF (Embedded Metric Format) enable high-cardinality business metrics without the cost of custom CloudWatch metrics.
Traces: Distributed tracing is the highest-value observability investment for serverless systems. Without traces, reconstructing a request's path through multiple services is nearly impossible.
OpenTelemetry as the Industry Standard
OpenTelemetry (OTel) has emerged as the de facto standard for serverless observability. As the second-largest CNCF project after Kubernetes, it provides a vendor-neutral framework for collecting logs, metrics, and traces, with a single agent. Key data points:
76% of organizations report OpenTelemetry adoption is at least somewhat important to their observability strategy (Logz.io Observability Pulse 2024).
89% of production users consider OpenTelemetry compliance critically important when evaluating observability vendors (Elastic 2026 report).
Organizations using OpenTelemetry report 50–72% cost reductions compared to proprietary agents, primarily through vendor portability and reduced lock-in.
OpenTelemetry Python SDK alone exceeds 224 million monthly downloads.
For AWS Lambda specifically, AWS provides the AWS Distro for OpenTelemetry (ADOT) as a Lambda Layer. It instruments functions without code changes and exports traces to X-Ray or any OTLP-compatible backend (Grafana Tempo, Jaeger, Datadog, New Relic).
Unique Serverless Observability Challenges
Context propagation across async boundaries: Traces must carry context through SQS message headers, EventBridge payloads, and SNS notifications. Without explicit context injection and extraction, traces break at async hops.
Ephemeral function lifespan: Functions may exist for a single invocation. Telemetry buffers must be flushed synchronously before the function exits; many libraries do not support forced flushing by default.
Cold start trace noise: INIT phase duration appears in traces and can skew latency percentiles if not separated from handler duration. Tag INIT vs. warm execution in dashboards.
Observability cost at scale: At 500 GB/month of Lambda logs, CloudWatch charges reach ~$250/month. Teams use telemetry pipeline tools to filter, sample, and pre-aggregate before export, reducing volume by 60–80%.
Best practice: Build observability into the function template, not as an afterthought. Every Lambda function should emit a structured JSON log on each invocation with: trace ID, function name, version, cold start flag, duration, and relevant business attributes. Use OTel auto-instrumentation where available to avoid manual span creation.
Vendor Lock-In: A Measured Assessment
Serverless architectures tend to accrete proprietary dependencies over time, event sources, managed databases, identity systems, and orchestration services. The degree of lock-in varies by how tightly business logic is coupled to provider-specific constructs.
Layers of Lock-In
Runtime lock-in (low risk): Function code written in Python or Node.js is largely portable. The handler interface is simple and can be wrapped for other runtimes.
Trigger lock-in (moderate risk): Functions triggered by S3 events, DynamoDB Streams, or Kinesis shards are coupled to AWS event schemas. Migrating to a different cloud requires replacing event sources and rewriting trigger logic.
Integration lock-in (high risk): Functions that directly call DynamoDB, SQS, Cognito, or other AWS-native services embed provider SDKs throughout business logic. Abstracting these behind interfaces reduces risk but requires architectural discipline.
Orchestration lock-in (high risk): AWS Step Functions, Azure Durable Functions, and Google Cloud Workflows use proprietary state machine definitions (ASL, JSON). Migrating multi-step workflows between providers is a significant rewrite.
Portability Strategies
Use the Hexagonal Architecture (Ports and Adapters) pattern: isolate cloud SDK calls behind interfaces, keeping business logic cloud-agnostic.
Adopt Knative or OpenFaaS for FaaS workloads on Kubernetes. These add operational overhead but provide genuine multi-cloud or on-premises portability.
CloudEvents (CNCF) provides a vendor-neutral event schema. Standardizing on CloudEvents reduces event format lock-in even when using cloud-native event buses.
Infrastructure as Code (Terraform over CDK/SAM) reduces deployment-layer lock-in and enables cross-cloud infrastructure definitions.
The AI Dimension: Serverless GPUs and Inference Workloads
A significant and rapidly expanding frontier is the intersection of serverless and AI inference. Traditional Lambda functions are CPU-bound and limited to 10 GB of memory, unsuitable for running LLMs or GPU-accelerated inference. A new category of serverless GPU platforms has emerged to fill this gap.
The Challenge: AI Workloads and Serverless Economics
AI workloads present a paradox for serverless: they require expensive, specialized hardware (GPUs), but their traffic patterns are often bursty and irregular, exactly the profile where serverless economics shine. Running a dedicated A100 GPU instance 24/7 at ~$3/hour costs over $2,100/month. A serverless GPU that bills only during inference eliminates idle cost.
A hybrid architecture has emerged as a pragmatic solution: use serverless Lambda functions (or Cloud Run) for orchestration, preprocessing, authentication, and lightweight logic, then route to GPU inference endpoints only when needed. Lambda absorbs orchestration overhead efficiently; GPU nodes handle the heavy lifting.
Serverless GPU Platform Landscape
As of early 2026, several platforms offer serverless GPU compute for AI workloads:
Platform | Key Strength | Cold Start | Best For |
Modal | Python-native, sub-second GPU provisioning | < 1 second | Custom model inference, ML pipelines |
RunPod Serverless | Wide GPU selection, cost-effective | 8–12 sec (Baseten); sub-200ms (RunPod) | Flexible AI/ML workloads |
Koyeb | Global serverless with GPU support | Low (web-optimized) | AI-enhanced web services |
AWS Lambda (CPU) | Integrated ecosystem, event-driven | < 1% of invocations | Orchestration, preprocessing |
Azure Container Apps + GPU | GPU support added 2024 | Container-based | Enterprise AI inference |
AWS is experimenting with GPU-accelerated Lambda, and NVIDIA is pushing serverless inference natively through Triton integrations. The boundary between GPU clusters and serverless functions is blurring.
Strategic Guidance for Production Serverless
The following guidance synthesizes production lessons, updated benchmarks, and architectural patterns for teams operating serverless at scale.
Decision Framework: When to Use Serverless
Use serverless when:
Traffic is bursty, irregular, or has significant idle periods (scale-to-zero saves real money).
The workload is event-driven, responding to S3 uploads, SQS messages, API calls, or scheduled triggers.
You need rapid iteration without infrastructure management overhead, particularly effective for small teams.
The function duration is short (under 15 seconds), and memory requirements are modest (under 3 GB).
Individual function costs are bounded and predictable (model cost per invocation before committing).
Avoid serverless when:
Traffic is steady-state and high-throughput; containers on Fargate or EKS will be 2–4x cheaper.
The workload is long-running (15+ minutes), stateful, or requires persistent connections.
Cold start latency is unacceptable, and the provisioned concurrency cost exceeds the problem's magnitude.
The workload is compute-intensive or GPU-dependent; use specialized serverless GPU platforms instead.
Debugging and local development parity are critical; container-based development is significantly easier to replicate locally.
Operational Readiness Checklist
Before promoting a serverless workload to production:
Observability: OpenTelemetry tracing instrumented, structured JSON logging enabled, CloudWatch alarms on Errors, Throttles, and Duration p99.
Cost model: Estimated monthly cost at P50, P95, and peak traffic levels. Budget alert configured.
Concurrency analysis: Reserved concurrency set per function based on profiling. Account-level quota increase requested if needed.
Cold start strategy: Cold start rate measured; mitigation (SnapStart, code optimization, provisioned concurrency) applied where SLA requires.
Dead-letter queues: Configured for all async invocations (SQS, SNS, S3) to capture failed events.
Memory tuning: Lambda Power Tuning run; memory allocation set to cost/performance optimum (not default).
Package size audit: Deployment package under 1 MB for Node.js, where possible; unnecessary dependencies removed.
The Convergence of Serverless and Containers
The architectural boundary between serverless and containers is dissolving. AWS Fargate, serverless compute for containers, lets teams deploy Docker images without managing nodes. Google Cloud Run, Azure Container Apps, and Knative on Kubernetes all blur the distinction further.
Most modern production architectures are hybrid: serverless functions for event-driven, short-lived work; containers for long-running services, stateful workloads, and compute-intensive tasks; serverless GPUs for AI inference bursts. Choosing the right runtime per workload is the mature approach, not a dogmatic commitment to any single model.
Conclusion
Serverless delivered on its core promises: it simplified deployment, enabled true event-driven elasticity, and democratized cloud-native development for teams without deep infrastructure expertise. For the right workloads, it remains one of the most effective and economical abstractions the cloud has produced.
But scale exposes tradeoffs that require deliberate management. Cold starts carry billing implications since the August 2025 INIT pricing change. The per-invocation cost model flips against you under sustained high-throughput. Account-level concurrency limits create invisible blast radii when not proactively managed. Observability is more complex, not simpler; it requires distributed tracing and structured telemetry from day one.
None of these challenges invalidates serverless. They clarify where it fits. The teams that extract the most value approach serverless intentionally: modelling costs before committing, instrumenting with OpenTelemetry from the start, tuning memory and concurrency based on real traffic data, and choosing containers or serverless GPUs when the workload demands it.
Serverless is a powerful option in the cloud-native toolkit. The best architectures do not choose between serverless and containers; they choose the right abstraction for each workload, apply it deliberately, and operate it with rigour.
Akava would love to help your organization adapt, evolve and innovate your modernization initiatives. If you’re looking to discuss, strategize or implement any of these processes, reach out to bd@akava.io and reference this post.