

Table of Contents
Traditional application patterns were not built for probabilistic systems, dynamic models, or continuous learning loops.
There is a meaningful difference between a product that uses AI and a product that is built around AI. Most organizations are still doing the first. The ones building durable competitive positions are doing the second, and the architectural gap between those two things is larger than it looks from the outside.
AI-native means the intelligence layer isn't a feature toggle or a third-party API wrapper. It's the primary interaction surface. The system's core value proposition depends on model behavior, and the architecture reflects that with data pipelines feeding real-time context, retrieval systems shaping model memory, orchestration layers managing multi-step reasoning, and observability tooling designed around probabilistic outputs rather than deterministic ones.
This guide covers the architectural decisions that matter at the platform level. Not which model to use that changes every six months anyway, but how to build systems around models that can absorb those changes without rewriting the product.
What Makes a Product AI-Native
The distinction matters because it shapes architectural choices from day one. An AI-enabled product adds intelligence to an existing interaction model, a search bar with better ranking, a form with auto-fill, and a dashboard with anomaly highlighting. The underlying system is still deterministic software with AI as an enhancement.
An AI-native product inverts this. The model is the interaction model. Think of a copilot that replaces a workflow interface, an agent that replaces a manual process, a personalization engine that replaces a static content layer. The user's primary engagement is with the AI's output, and the software exists to configure, constrain, and contextualize that output.
Dimension | AI-enabled | AI-native |
Core value | Traditional feature set, AI enhances | AI output is the product |
Architecture | AI as an add-on service | AI as primary orchestration layer |
Failure mode | Feature degrades, core works | Model failure = product failure |
Iteration cycle | Feature sprints | Eval → prompt → model → deploy loops |
Key dependency | Backend APIs | Data quality, context architecture, evals |
Moat | Feature depth | Data flywheel + evaluation infrastructure |
The practical implication: if your product depends on AI-native interaction patterns, your engineering org needs to be organized around that dependency. An AI team bolted onto a traditional engineering structure will be perpetually behind, constantly negotiating for data access and infrastructure they should have owned from the start.
Traditional software assumes deterministic outputs. Given the same input, the system returns the same output. AI-native systems are probabilistic; the same input can produce meaningfully different outputs across runs, models, and time. Every architectural assumption downstream of that, including caching, testing, monitoring, and user trust, has to be rebuilt with this in mind.
Core Architecture Layers
Five layers every AI-native product needs to get right and the failure modes that appear when one of them is underbuilt.
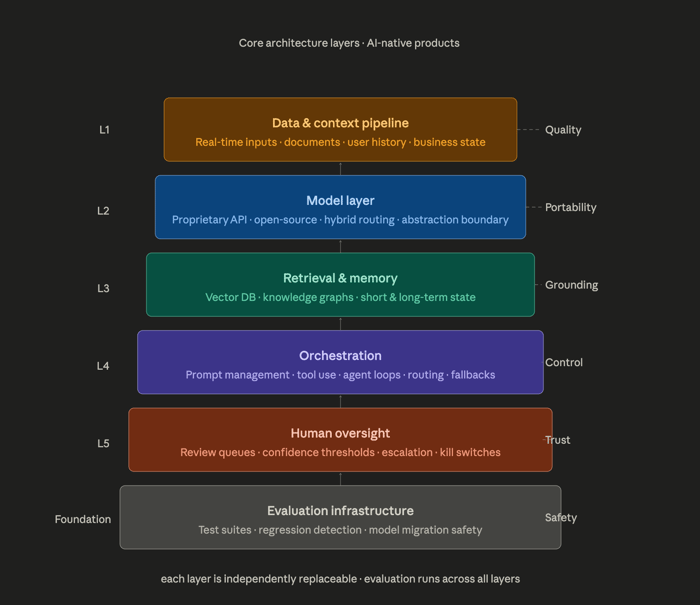
The layer model
Layer 1 Data & context pipelineReal-time inputs, structured documents, user history, and business state assembled into the context window. Quality here determines quality everywhere. A bad retrieval pipeline makes a great model useless. | Layer 2 Model layerProprietary API, open-source self-hosted, or hybrid by use case. Not a permanent choice an abstraction boundary. The model layer should be swappable without rebuilding the orchestration layer above it. |
Layer 3 Retrieval & memoryVector databases, knowledge graphs, and conversation state. Short-term context, long-term user memory, and domain knowledge retrieval each have different latency and freshness requirements. | Layer 4 OrchestrationPrompt management, tool use, multi-step reasoning chains, and agent loops. This layer coordinates what the model does and in what order. It also handles routing, fallbacks, and human escalation. |
Layer 5 Human oversightReview queues, confidence thresholds, escalation paths, and kill switches. Not optional for mission-critical use cases. Designed before launch, not retrofitted after the first incident. | Layer 6 Evaluation infrastructureThe layer that validates every other layer. Test suites run on every prompt change, model upgrade, and data pipeline update. Without this, you cannot safely iterate on any other layer. |
Model selection: proprietary vs open-source vs hybrid
The model selection question is less a technology decision than an operational one. Proprietary APIs (Anthropic, OpenAI, Google) give you the capability immediately, but create vendor dependency and can change pricing, terms, or capability without notice. Open-source models (Llama, Mistral, Qwen) give you control but require infrastructure investment and in-house expertise to operate. Hybrid strategies, proprietary for complex tasks, open-source for high-volume simpler tasks, are becoming the default at scale.
Strategy | When it makes sense | Primary risk | Infra cost |
Proprietary API only | Early stage, moving fast, limited ML infra | Vendor lock-in, cost at scale | Low |
Open-source self-hosted | Data sovereignty, cost control, custom tuning | Capability gap, ops overhead | High |
Hybrid routing | Mature product, multiple use cases, cost optimization | Routing logic complexity | Medium |
Fine-tuned open-source | Domain-specific tasks, latency-critical, large volume | Eval coverage, training pipeline | Very high |
Retrieval architecture: the part most teams get wrong
Retrieval-Augmented Generation (RAG) is now table stakes for AI-native products that need grounding in proprietary data. But most initial RAG implementations are naive: a single vector store, cosine similarity retrieval, and chunk-and-stuff into context. This works in demos and breaks in production.
Production retrieval requires thinking about the retrieval pipeline as a data system with its own quality requirements: chunking strategies that preserve semantic coherence, hybrid retrieval combining dense vectors and sparse keyword matching, re-ranking models that improve precision over raw similarity, and freshness pipelines that keep the knowledge base current. The retrieval layer is often where hallucination rates are improved most cheaply; better context means the model has less reason to confabulate.
Operating AI Systems in Production
Building an AI-native product and operating one are genuinely different disciplines. Many teams find the second harder than the first. Production AI systems introduce failure modes that don't exist in traditional software: silent quality degradation, stochastic errors that reproduce inconsistently, model drift when the provider updates quietly, and cost spikes triggered by input distribution shifts.
Observability for probabilistic systems
Traditional APM tools' latency, error rate, and throughput are necessary but not sufficient. AI-native systems need a second observability layer that tracks behavioral quality: output relevance, factual accuracy, tone consistency, and task completion rates. Neither layer replaces the other; they answer different questions.
Signal type | What it detects | Tooling approach |
Latency & throughput | Infrastructure degradation | Standard APM (Datadog, Grafana) |
Token consumption | Cost anomalies, prompt bloat | LLM observability (Helicone, LangSmith) |
Refusal rate | Guardrail over-trigger, input shift | Custom dashboards on model outputs |
Output quality | Quality drift, hallucination rate | LLM-as-judge, human sampling |
User signals | Satisfaction, task completion | Product analytics + thumbs up/down |
Model version drift | Provider-side changes affecting behavior | Eval suite run on canary traffic |
Cost management: the economics of inference
Token cost is the line item that surprises most engineering teams when they reach scale. A product that costs $0.02 per session in testing can easily reach $0.40 per session in production if context windows expand, retry logic is aggressive, or input classification sends more queries to expensive models than intended.
Cost management is an architectural concern, not an ops afterthought. The decisions that most affect inference economics are made at design time: how large the context window is, whether to use a cheaper model for classification before routing to a premium one, how aggressively to cache deterministic outputs, and where in the pipeline to truncate or summarize long inputs.
Rules of thumb for inference cost
Classify before you generate a fast, cheap model, deciding "does this query need the expensive model" saves significant spend at volume. Cache aggressively for inputs that recur. Set context window budgets per use case and enforce them at the orchestration layer, not at the prompt level. Measure cost per user action, not per API call; the latter hides inefficiency.
Security, privacy, and governance
AI-native products introduce a security surface that most traditional security frameworks don't cover: prompt injection, context poisoning, indirect instruction hijacking via retrieved documents, and data exfiltration through model outputs. These aren't theoretical risks; they are active attack vectors.
Governance requirements add a second dimension. Regulated industries (finance, healthcare, legal) face obligations around explainability, auditability, and human review that AI-native architectures must accommodate. This means designing audit trails, confidence scoring, escalation paths, and output review workflows before you're forced to retrofit them under pressure.
Strategic guidance for CTOs
Five decisions that determine whether an AI architecture becomes a competitive asset or a maintenance liability.
Build use-case first, not model-first. The most common failure mode is choosing a model and working backwards to find it a job. Start with the workflow you're replacing or enhancing, define what "good" looks like precisely enough to measure it, then select the model and architecture that satisfies those requirements. Use-case clarity is also how you build evaluation criteria; without it, you're optimizing blind.
Design for model portability from day one. The model you ship with is unlikely to be the model you run in two years. Anthropic, OpenAI, Google, and Meta are all shipping significant capability improvements on sub-12-month cycles. Build an abstraction layer between your orchestration logic and the model API. Your product logic should speak in terms of tasks and capabilities, not model-specific parameters and token formats.
Build a shared AI platform, not isolated experiments. Multiple product teams, each building their own LLM wrappers, evaluation scripts, and observability dashboards, is how you accumulate technical debt at AI speed. An internal AI platform team owning the shared prompt registry, eval infrastructure, observability stack, and model routing creates leverage across every product team and enforces consistent security and governance practices.
Align product, engineering, legal, and operations before you ship. AI-native products have cross-functional failure modes. A quality regression that looks like an engineering problem might be a data issue. A compliance gap that surfaces in legal review might be an architecture decision made six months earlier. The teams that ship AI features reliably have standing cross-functional AI governance, not a committee, but a shared accountability model with clear decision rights.
Invest in evaluation infrastructure before you need it. Eval is the boring part of AI architecture that determines whether you can safely iterate on everything else. Teams that deprioritize it in the name of velocity discover, usually at the worst time, that they cannot confidently ship model upgrades, cannot detect quality regressions, and cannot migrate off a deprecated model without months of manual testing. Evaluation infrastructure is not technical debt repayment, it is the foundation for speed.
"The organizations that win on AI will not be those who moved fastest in 2024. They will be the ones who built the infrastructure to move safely and repeatedly in 2026 and beyond."The model landscape will look different in 18 months. Prices will drop. Open-source capabilities will close the gap. New modalities, voice, vision, and action will become table stakes. The organizations positioned to take advantage of these changes will have invested in the architectural layer underneath the models: the data pipelines, evaluation harnesses, retrieval systems, and platform tooling that make model upgrades a routine operation rather than an engineering crisis.
AI architecture is not a one-time design decision. It is a core engineering competency one that compounds over time the way any well-maintained platform does. The CTO's job is not to pick the right model. It is to build a system that can keep up with whatever models come next.
Akava would love to help your organization adapt, evolve and innovate your modernization initiatives. If you’re looking to discuss, strategize or implement any of these processes, reach out to bd@akava.io and reference this post.


