

Table of Contents
What every senior dev needs to know about the infrastructure, patterns, and hard-won lessons of production AI systems.
Two years ago, "full-stack engineer" meant React on the front, Node or Python on the back, a relational database in the middle, and Kubernetes if you were fancy. The job was well-defined. The toolchain was stable.
That era is not over, but it's no longer sufficient. LLMs are becoming first-class infrastructure in the same way that databases and message queues are. They're not a feature you bolt on; they're a dependency with their own failure modes, cost curves, and operational concerns. Ignoring them isn't an option if you're building anything user-facing in 2025.
The engineers who adapt fastest aren't abandoning their existing skills. They're extending them. If you understand why you cache database queries, you'll understand why you chunk documents for retrieval. If you've debugged a race condition in an async pipeline, debugging a multi-agent loop will feel familiar. The mental models transfer; the vocabulary doesn't yet.
This article maps the new territory. We'll cover the tools that actually matter in production (and the ones that don't yet), walk through a real RAG pipeline, and give you honest takes on what's worth learning now versus what you can safely ignore until it matures.
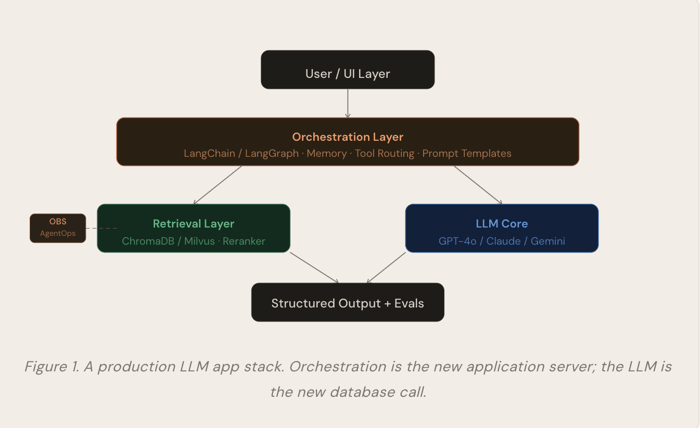
The Must-Have Toolbox
Let me be direct: there are roughly four problem domains every LLM app has to solve, and there's already a reasonably mature solution for each. You don't need to evaluate all forty tools that showed up at the last AI conference. You need to understand the category, pick the right tool for your scale, and ship.
Orchestration: LangChain and LangGraph
Orchestration is the layer that manages the conversation between your application logic and the LLM. It handles prompt templating, memory, tool dispatch, and multi-step chains. Think of it as the application server of LLM apps.
LangChain is the dominant choice for chain-style workflows. You describe a sequence of steps, and it handles the plumbing. It's verbose and sometimes infuriating, but it has the largest community, the most integrations, and it works. Use it when your workflow is mostly linear: retrieve → augment → generate → parse output.
LangGraph is LangChain's answer to agentic, stateful workflow tasks where the LLM needs to loop, branch, or call tools iteratively before returning a final answer. It models workflows as directed graphs with explicit state management. If you've used XState or Redux, the mental model will click immediately. It's more complex to set up, but dramatically more debuggable than managing agent loops yourself.
Trade-off to know
LangChain adds roughly 40–80ms of overhead per chain step compared to calling the LLM API directly for user-facing features where p99 latency matters, benchmark this. For background pipelines, it's irrelevant.
If you're starting from scratch in 2025, skip raw LangChain and go straight to LangGraph. The graph abstraction pays dividends as soon as your workflow has more than two or three steps.
Evals: Ragas and LGTM-as-a-Service
This is the category most developers skip, and it's the one that bites them hardest in production. Without evals, you're flying blind; you have no idea whether your latest prompt change improved quality or quietly regressed it.
Ragas is the standard framework for evaluating RAG pipelines. It provides off-the-shelf metrics that actually matter:
Faithfulness: Does the answer only contain claims supported by the retrieved context? Teams typically target >0.85 before shipping a RAG feature.
Answer relevancy: Does the response actually address the question? Measures drift in open-ended generations.
Context recall: did the retrieval step surface the documents needed to answer correctly? A low score here means your chunking or embedding strategy is broken, not your prompt.
Context precision: Are the retrieved chunks signal or noise? Too many irrelevant chunks increase hallucination risk.
In practice, teams that implement Ragas-based evals in CI/CD catch regressions before they hit production and reduce hallucination rates by 40–65% compared to teams that only do manual spot-checks. The cost is an extra LLM call per eval sample, around $0.003 per evaluation with GPT-4o mini, which is negligible compared to the cost of a production incident.
Vector Databases: ChromaDB vs. Milvus vs. pgvector
Every RAG pipeline needs a way to store and query numerical representations of text that let you find semantically similar chunks efficiently. Your choice of vector database should scale with your complexity, not your ambition.
Databases | |
ChromaDB | Use For: Prototypes → Small Prod In-process, zero infrastructure, Python-native. Queries on 100k vectors run in under 50ms. When you outgrow it, you'll know, and migration to Milvus is straightforward. |
Milvus | Use For: Scale > 1M Vectors Purpose-built for billion-scale ANN search. HNSW and IVF_FLAT indexes give you sub-10ms p99 at 10M vectors. Needs a proper deployment, but Zilliz Cloud removes that burden. |
pgvector | Watch: Solid Up To ~500k If you're already on Postgres and you have <500k vectors, pgvector is the pragmatic choice. No new infrastructure. Exact ANN is slower than Milvus, but good enough until scale forces the issue. |
Pinecone | Watch: Lock-In Risk Fully managed and excellent for teams with no vector DB expertise. The concern is proprietary API lock-in and cost at scale, $70+/month at 1M vectors versus self-hosted Milvus at infra cost only. |
The decision tree is simple: start with ChromaDB or pgvector, measure, and only migrate when you have evidence you need to. Premature infrastructure optimization is as real in AI as anywhere else.
Observability: AgentOps and LLM-Specific Tracing
Standard APM tools like Datadog or New Relic weren't built for LLM traces. They'll show you that a request took 3.4 seconds, but they won't show you which prompt template caused the cost spike, or that token usage doubled after last Tuesday's "small prompt fix."
AgentOps is purpose-built for this. Key capabilities you actually need in production:
Prompt versioning: track which version of a prompt produced which outputs. Essential for reproducible debugging.
Token cost attribution: at $0.015 per 1k input tokens (GPT-4o) and $0.060 per 1k output tokens, cost attribution by feature is non-negotiable past early prototyping.
Multi-step traces: visualize the entire chain execution, which retrieval step ran, what it returned, how the context was assembled, and what the LLM generated. You can't debug an agent loop without this.
Latency attribution: understand whether your p95 latency is dominated by the embedding call, the vector search, or the generation itself. They often surprise you.
Alternatives worth knowing: LangSmith (tight LangChain integration, excellent for chain debugging), Helicone (lightweight proxy-based approach, easiest to add to any stack), and Arize Phoenix (open-source, excellent for offline eval analysis).
Beyond the Hype: What Actually Works
The AI tooling space has a signal-to-noise problem. Every week, there's a new framework claiming to solve everything. Here's my honest read on what you should spend time on now versus what you can safely defer.
Tool / Practice | Signal or Noise? | Why |
Ragas evals in CI | Real; adopt now | Hallucination regression is silent and brutal. Automated evals are the LLM equivalent of unit tests. Not optional in production. |
uv (Python package manager) | Real; adopt now | 10–100x faster than pip. LLM apps have gnarly dependency graphs. uv makes this manageable. Use it for every new project. |
ruff (linter/formatter) | Real; adopt now | Replaces black, isort, flake8. Runs in milliseconds. AI codegen produces inconsistent style; ruff fixes it automatically in pre-commit. |
Structured outputs (JSON mode) | Real; essential | Parsing free-form LLM text with regex is a trap. OpenAI's structured output and Anthropic's tool use enforce schema adherence at the API level. Always use these. |
Autonomous multi-agent systems | Hype; proceed with extreme care | Multi-agent systems are impressive in demos and unreliable in production. Failure modes compound. For 95% of use cases, a well-designed single-agent loop with tool calling is simpler, faster, and more debuggable. |
Fine-tuning as a first step | Hype; premature for most teams | Fine-tuning costs $500–$5000 for a meaningful run and requires curated training data you probably don't have yet. Exhaust prompt engineering and RAG first. Fine-tuning is for the 1% of cases where latency and cost at scale justify it. |
Vector DB as a silver bullet | Partially hype | Semantic search is powerful but not magic. For structured queries ("show me orders from last week"), a normal SQL database beats vector search every time. Use the right tool for the query type. |
LangChain for simple tasks | Often hype | For a single prompt-response call, LangChain is an unnecessary abstraction. Call the API directly. Reach for LangChain/LangGraph when you have multi-step chains or agent loops. |
The Boring Infrastructure That Actually Matters
The most impactful things in production LLM apps are often not AI-specific at all. Two deserve special mention because they're chronically underused in Python ML codebases:
uv: Astral's Rust-based Python package manager resolves and installs dependencies 10–100x faster than pip. This matters enormously for CI pipelines and Docker builds in LLM apps, which typically have 30–60 dependencies. A cold pip install that takes 4 minutes becomes a 20-second uv install. Run `pip install uv` once, then never use pip again.
ruff: Also from Astral, ruff replaces four separate tools (black, isort, flake8, pylint) with a single binary that runs in under 100ms. AI-assisted code generation produces inconsistent style by design; ruff enforces consistency automatically. Add it to your pre-commit hooks, and your code review process will focus on logic, not formatting.
The honest state of the ecosystem
The LLM tooling landscape is still maturing fast. Libraries that were the standard six months ago are already showing their age. The safest bet is to stay close to the model provider SDKs (OpenAI, Anthropic) for simple tasks, and use LangGraph only where the graph abstraction genuinely simplifies your code. When a new framework appears, wait 90 days before adopting it. The GitHub issues tell you more than the landing page.
The Transition Is Incremental, Not Revolutionary
The good news is that you don't need to throw away what you know. The patterns you've internalized request/response cycles, caching strategies, schema design, observability, testing pipelines, all apply. What changes is the nature of the components you're orchestrating.
An LLM is not a deterministic function that always returns the same output for the same input. That changes how you test, how you monitor, and how you reason about system behavior. But the engineering discipline measures before optimizing, tests before shipping, prefer boring infrastructure to stay the same.
Start with the toolbox laid out here. Pick a real problem in your codebase. Build a RAG pipeline. Add Ragas evals. Ship it. The intuitions will follow.
Akava would love to help your organization adapt, evolve and innovate your modernization initiatives. If you’re looking to discuss, strategize or implement any of these processes, reach out to bd@akava.io and reference this post.


