

Table of Contents
The discipline determining AI production success is what engineering organizations need to focus on now.
There was a window roughly from 2023 to early 2024 when "prompt engineer" felt like one of the most important job titles in tech. Teams hired specialists who could coax better outputs from GPT-4, who knew the right incantations to keep a model on task, who could write a system prompt that somehow made a customer service bot actually helpful. That era is not quite over, but its centrality is.
Prompt engineering captured early attention in the generative AI wave. Teams rushed to hire specialists who could craft clever prompts, unlock better outputs, and squeeze performance from large language models. But as organisations move from demos to production systems, it’s becoming clear that prompt engineering alone isn't the job. Writing prompts are only a small piece of what it takes to operate AI reliably at scale.
The real challenge is Prompt Ops: the discipline of managing prompts as living production assets. This includes version control, testing, evaluation, monitoring, governance, cost management, security, and continuous improvement across changing models and business requirements. Just as DevOps transformed software delivery and MLOps matured machine learning systems, Prompt Ops is emerging as the operational layer for LLM-powered products.
This article explores why the market is shifting from prompt craftsmanship to prompt operations, what teams need to build sustainable AI systems, and how engineering organizations can move beyond one-off prompt hacks toward repeatable business value.
Why Prompt Engineering Was Overhyped
To be precise: prompt engineering was never a bad idea. Knowing how to structure a chain-of-thought, when to use few-shot examples, and how to decompose a complex task all of that matters and continues to matter. The problem was the implied scope. Prompt engineering was sold as the lever. In production, it turns out to be one lever among many, not always the most important.
Several things happened simultaneously to deflate the hype:
Models got smarter and more instruction-following. The clever prompt tricks that unlocked performance from GPT-3 elaborate role-playing setups, unusual formatting constraints, elaborate chain-of-thought scaffolding, became largely unnecessary with later models. GPT-4, Claude, and Gemini-class models follow natural instructions well. The moat of prompt expertise shrank considerably.
Production broke the demo assumptions. A prompt that works beautifully in a Jupyter notebook tends to degrade in the real world. Users ask unexpected things. Edge cases compound. Data passed into the context varies in ways you didn't anticipate. The prompt was authored assuming a clean setup; production provides chaos.
Reliability became the real requirement. Executives and product managers don't care if your AI outputs sound more natural than a competitor's. They care whether the output is consistently accurate, safe, and on-brand. That kind of reliability isn't something you craft into a prompt; it's something you build into a system over time.

What Prompt Ops Actually Means
The shortest definition: Prompt Ops is the practice of treating prompts as production assets, not static text.
When a software team says they do DevOps, they mean they've built a culture and toolchain around reliable software delivery, version control, CI/CD, monitoring, and incident response. Prompt Ops draws the same boundary around the AI prompt lifecycle. A prompt is not a string someone typed once and deployed. It's a living artifact that changes when models change, when business requirements shift, and when new failure modes are discovered.
Prompt Ops is the set of practices, tools, and organizational structures that govern how prompts are authored, tested, deployed, monitored, and improved across the full lifecycle of an LLM-powered product.
The Prompt Ops lifecycle

Authoring with structure: Prompts live in a repository alongside application code. They have owners, changelogs, and metadata, which models they target, which products they serve, and which use cases they're scoped to. Templates and shared components reduce duplication across teams.
Evaluation before deployment: Every prompt change runs through an evaluation suite, a set of test cases with expected outputs (or expected properties of outputs). A regression in accuracy, tone, or safety blocks the change just as a failing unit test would block a code push.
Controlled rollout: New prompt versions ship to a slice of traffic first 5%, then 20%, then full. A/B tests compare behavioral and business metrics between old and new versions before a full cutover. Rollbacks happen the same way code rollbacks do.
Runtime monitoring: Output quality, latency, token consumption, and failure rates are tracked in dashboards. Alerts fire on anomalies: a sudden spike in refusals, a drop in user satisfaction scores, a hallucination rate crossing a threshold. Drift detection compares production outputs to your evaluation baseline over time.
Continuous improvement: Failure cases from production feed back into the evaluation suite. Human review of sampled outputs identifies new patterns. Model upgrades trigger re-evaluation of every prompt in the library against the new model before any migration happens.
Building the Prompt Ops Stack
There's no single vendor that provides the full Prompt Ops stack at least not yet. What exists today is a combination of purpose-built tooling, extended uses of existing infrastructure, and internal platforms that organizations build themselves.
Here's how to think about the layers:
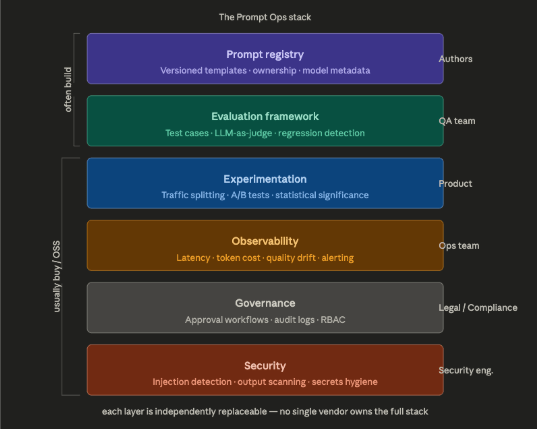
Layer 1 Prompt registryVersion-controlled storage for prompt templates, organized by product, model, and use case. Git works. Dedicated tools like Langfuse, PromptLayer, or Weights & Biases Prompts add metadata and UI on top. The key property: every prompt has an addressable version ID. | Layer 2 Evaluation frameworkA test harness that runs your prompt + test inputs through the model and scores outputs. Scoring can be rule-based (regex, JSON schema), model-based (LLM-as-judge), or human-in-the-loop. Tools: Braintrust, PromptFoo, RAGAS, or a custom eval runner in Python. |
Layer 3 ExperimentationInfra for A/B testing prompt variants against live traffic. Requires routing logic, a metric collection layer, and statistical significance testing. Often built on top of existing feature flag infrastructure (LaunchDarkly, Unleash) with prompt-specific adaptations. | Layer 4 ObservabilityTracing every LLM call with its inputs, outputs, latency, token counts, and model version. Aggregated dashboards for cost per workflow, per user, per feature. Alerting on quality regressions. Tools: LangSmith, Helicone, Arize, or OpenTelemetry with custom spans. |
Layer 5 GovernanceApproval workflows for prompt changes that affect safety, compliance, or regulated outputs. Audit logs of who changed what and when. Role-based access: who can author, who can approve, who can deploy to production. | Layer 6 SecurityInjection detection in user-supplied inputs. Output scanning for sensitive data exfiltration. Rate limiting and abuse detection at the prompt execution layer. Prompt templates stored with secrets hygiene no credentials hardcoded in system prompts. |
Prompt Ops vs adjacent disciplines
Practice | Primary concern | Overlap with Prompt Ops | Distinct from Prompt Ops |
Prompt engineering | Crafting effective prompts | Authoring phase | No lifecycle management |
MLOps | ML model training & serving | Monitoring, versioning patterns | Prompt Ops assumes APIs, not model ownership |
LLMOps | LLM infra: serving, fine-tuning | Observability, cost management | LLMOps is model-layer; Prompt Ops is application-layer |
DevOps | Software delivery reliability | CI/CD patterns, version control, rollback | Prompt Ops adds eval and behavioral testing |
AI Safety / Red-teaming | Model and system safety | Injection defense, output scanning | Safety is a property Prompt Ops must preserve, not owns |
Consider a SaaS company using Claude to generate draft customer emails. Their prompt engineering team wrote a strong initial prompt and shipped it. Six weeks later, Anthropic released a new model version. The new model writes in a slightly different register subtly more formal. No test caught it. A batch of 40,000 customer emails went out in a style customers found off-brand. The prompt hadn't changed. The infrastructure around it had no mechanism to notice. That's the Prompt Ops gap.
Strategic Implications for Teams
Prompt Ops doesn't just change tooling choices, it changes how teams are organized and what skills matter. The following observations come from organizations that have moved AI features from pilot into sustained production operations.
New roles emerging | |
AI Platform Engineer | Builds and maintains the shared Prompt Ops infrastructure, the registry, the eval runner, observability stack. Analogous to a platform engineer in software teams. Usually sits in a central platform or developer experience org. |
Prompt Operations Lead | Owns the end-to-end lifecycle for a product area's prompts. Writes evals, reviews production monitoring, and coordinates model migrations. Requires both technical and product judgment. This role doesn't exist in most job families, yet it's usually a prompt engineer or ML engineer adapting their scope. |
AI QA Engineer | Specializes in behavioral testing of AI outputs, writing diverse test cases, identifying failure distributions, and running adversarial inputs. Closer to traditional QA than to ML research, but requires an understanding of LLM failure modes. |
AI Product Manager | Responsible for defining quality bars, prioritizing eval coverage, and making rollout decisions. The AI equivalent of a release manager. Needs to be literate in evaluation metrics and comfortable with ambiguity. |
The collaboration model is non-negotiable
One of the most common mistakes is treating Prompt Ops as purely an engineering concern. It isn't. The people who best understand what "good" looks like for an AI output are often in customer success, legal, compliance, or product. Engineering can build the evaluation infrastructure, but the test cases and quality criteria have to come from the business.
This means Prompt Ops requires ongoing conversations between product, engineering, and whoever understands the domain well enough to judge output quality. Teams that wall this off in an AI team tend to optimize for the wrong metrics and are surprised when outputs fail in ways users notice, but dashboards don't.
Make-vs-buy decisions at each layer
Not every layer of the Prompt Ops stack warrants a build. Here's a practical frame:
Stack layer | Build | Buy / OSS | Starting point |
Prompt registry | If you have unique metadata needs | Most teams | [OSS] Git + Langfuse |
Evaluation | For domain-specific scorers | Base framework | [OSS] PromptFoo or Braintrust |
Experimentation | If you have existing feature flag infra | Smaller teams | [Buy] LaunchDarkly extension |
Observability | Only at a very large scale | Almost always | [Buy] LangSmith or Helicone |
Governance | Regulated industries | Others | [Build] Custom approval workflows |
Security | Rarely | Usually | [OSS] Rebuff, Presidio, custom guards |
Model migrations are the stress test
Every organization using GPT-4, Claude 2, or an early Gemini model will eventually face a model migration. The model vendor deprecates the version, or a newer model has capabilities you need, or the price-performance ratio changes. This is where Prompt Ops proves its value.
Without it: you find out the new model behaves differently when users start complaining.
With it: you run your full eval suite against the new model, identify the prompts that regress, fix them before cutover, and migrate with confidence. The difference in cost and risk is substantial. Teams without eval coverage typically spend two to three months on a model migration that should take two to three weeks.
The bottom line
Prompts matter. The craft of writing clear, effective instructions for a language model is a real skill, and it's not going away. But in the context of production AI systems, the prompt is table stakes. The operational infrastructure around it is what separates a product that works reliably from one that works in the demo.
If you're building or managing AI features at any scale, dozens of prompts, multiple products, and a team larger than one, the questions worth asking are operational ones: Do you know what version of your prompt is running in production right now? Could you detect a quality regression within hours rather than weeks? If Anthropic or OpenAI deprecates the model you're using next quarter, do you have a migration path that doesn't require months of manual re-testing?
The organizations that answer yes to those questions will ship AI features faster, recover from failures more confidently, and iterate without fear. Prompt engineering gave teams the ability to communicate with models. Prompt Ops gives them the ability to trust what those models do in production.
The prompts matter. The operations determine the outcome.
Akava would love to help your organization adapt, evolve and innovate your modernization initiatives. If you’re looking to discuss, strategize or implement any of these processes, reach out to bd@akava.io and reference this post.


